Vellum - Build production-worthy LLM applications
The developer platform for building production-worthy Large Language Model applications
TL;DR Vellum (W23) is a developer platform for building production-worthy applications on LLMs like @OpenAI’s GPT-3 or @Anthropic’s Claude. Use Vellum to save hours on prompt engineering, iterate on prompts in production confidently, and continuously fine-tune for better results (we helped one customer save 94% of their LLM costs through fine-tuning!). Request early access here.
—
Hi everyone,
Akash, Noa and Sidd here. We worked together at Dover (YC S19) for 2+ years where we built production use-cases of Large Language Models (LLMs). Noa and Sidd are MIT engineers who previously worked at DataRobot’s MLOps team and Quora’s ML Platform team respectively.
We decided to work on Vellum after realizing that while the MLOps industry has matured rapidly for traditional ML, companies using LLMs don’t have any of this tooling available. Engineering teams spend many hours building custom internal tooling to tame LLMs, taking away time from building their core product.

The LLM Management Problem
We’ve seen companies building production applications with Large Language Models experience challenges at all stages:
- Going from 0 → 1: ”Prompt engineering” has become an important role in working with LLMs. Today, most people experiment with various prompts across browser tabs and the more diligent track the results of their experimentation in spreadsheets. Rarely do people take the time to test each variant across a sufficient number of test cases, let alone try different parameter combinations and LLM providers. Most settle for a sub-optimal configuration because the testing process is so tedious. Querying for semantically relevant context against a corpus of text to inject in the prompt is another large barrier for many people just getting started.
- Managing changes once live in production: Tracking model & prompt versions, keeping an audit log of inputs/outputs, testing changes to prompts/models before going into production, and measuring aggregate quality metrics are all critical for a production-worthy system, but all require custom code and non-trivial internal tooling. Engineers don’t have time to build out this tooling and instead, fly blind – never sure what their current baseline for quality is or whether “improvements” made to their prompts will in fact break existing behavior.
- Post-MVP optimization: Most people find a semi-reasonable prompt for text-davinci-003 and move on. But, they also acknowledge that with more time, they could set up a fine-tuning pipeline, experiment with other models/LLM providers, and try out new foundation models as they’re released to maximize output quality while dramatically reducing LLM provider spend. They’re paying a premium for sub-optimal quality and risk falling behind as new models are released.
The Vellum Product
We have 3 products – each aimed to solve the problems we identified when building production LLM apps ourselves.
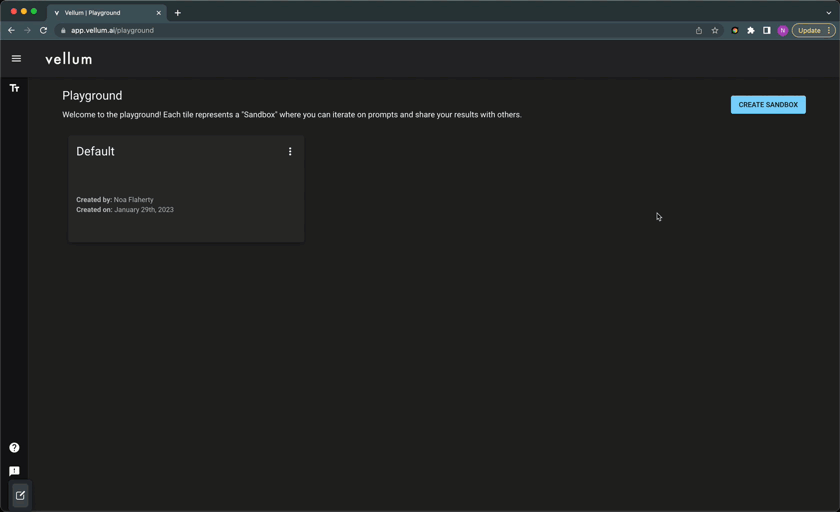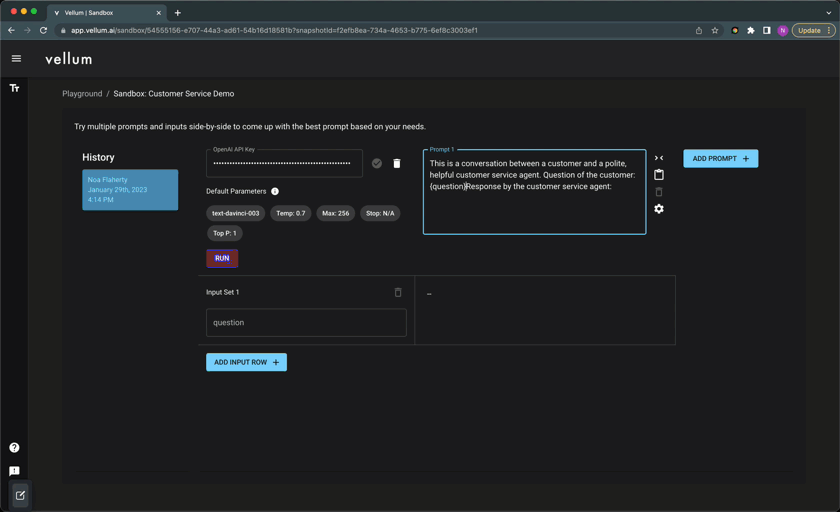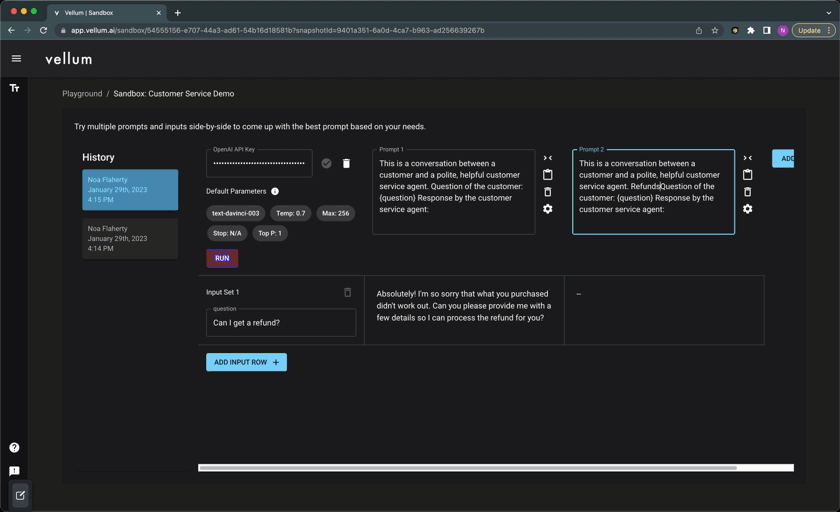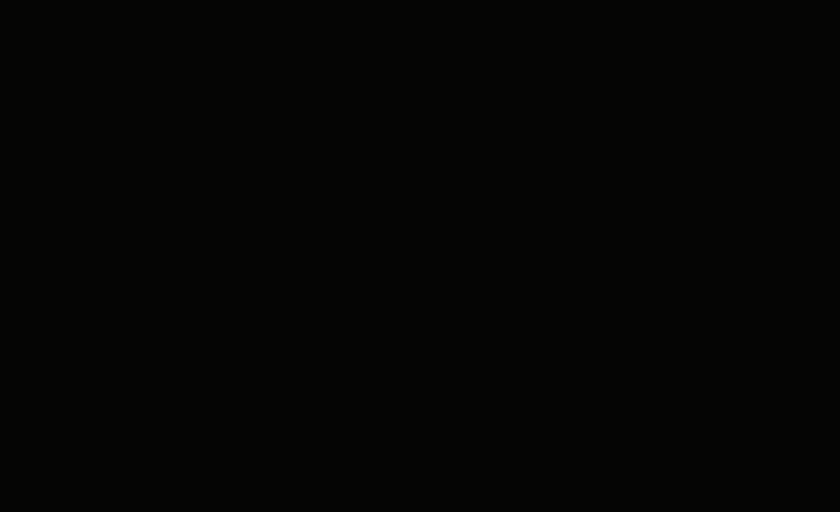
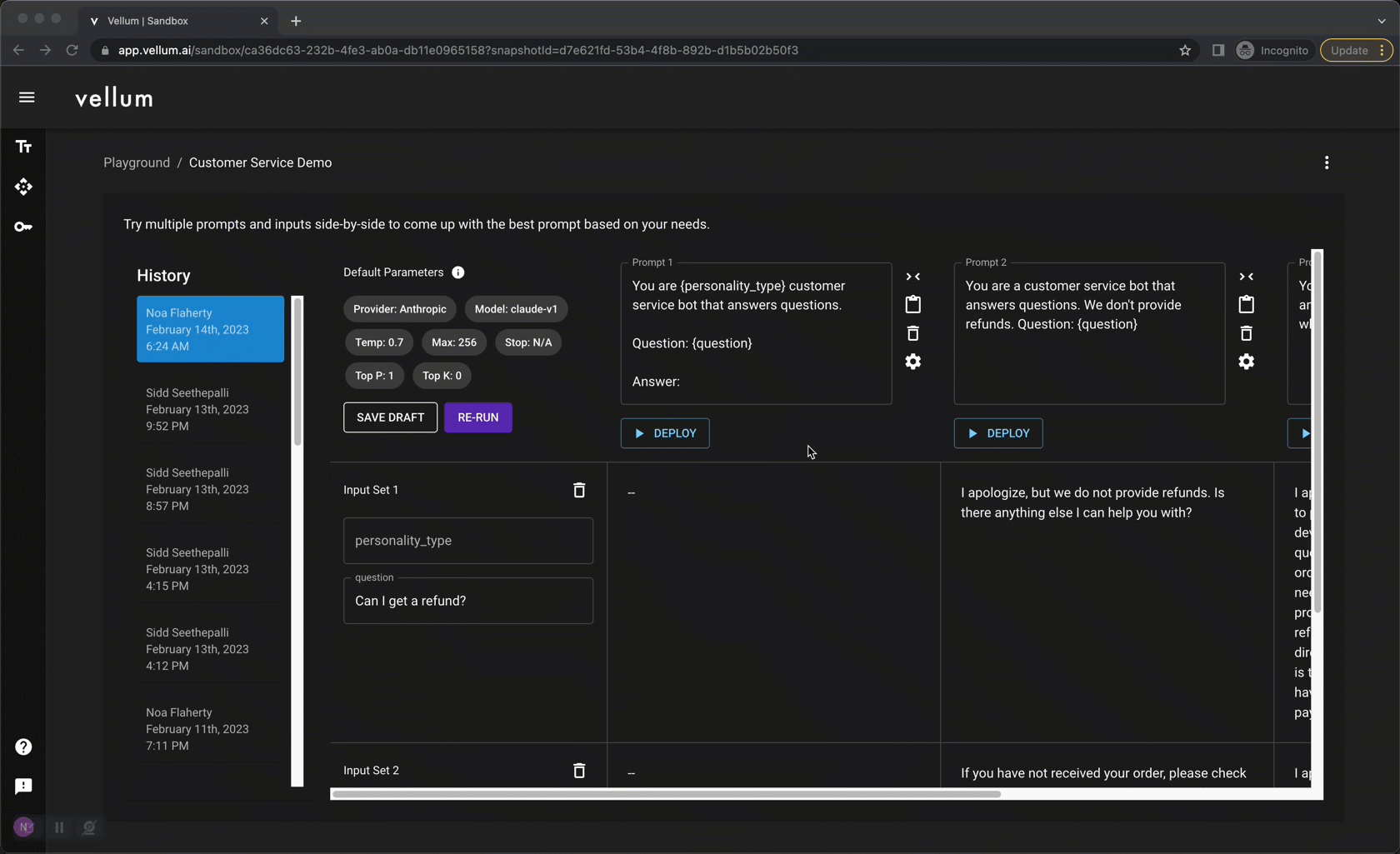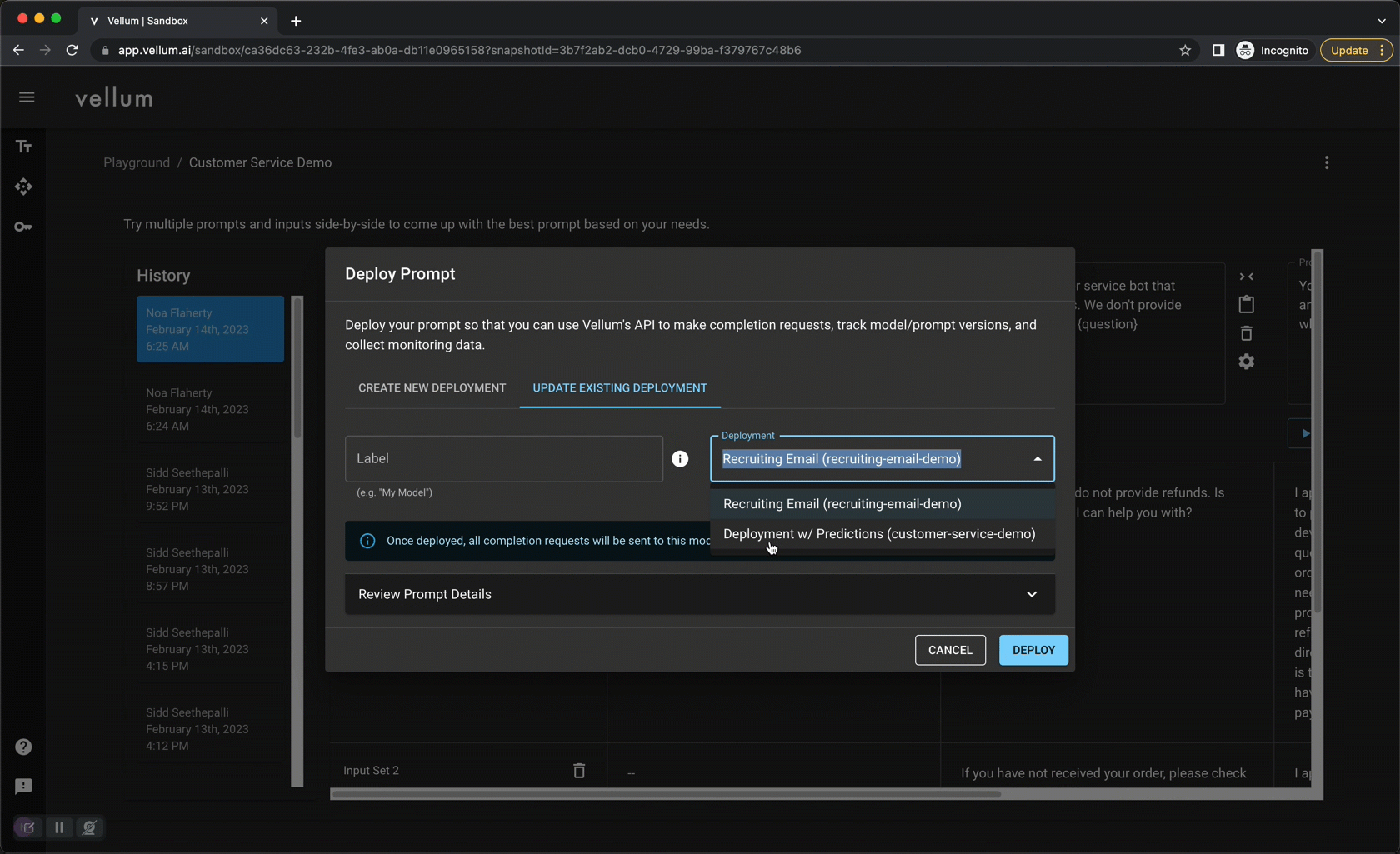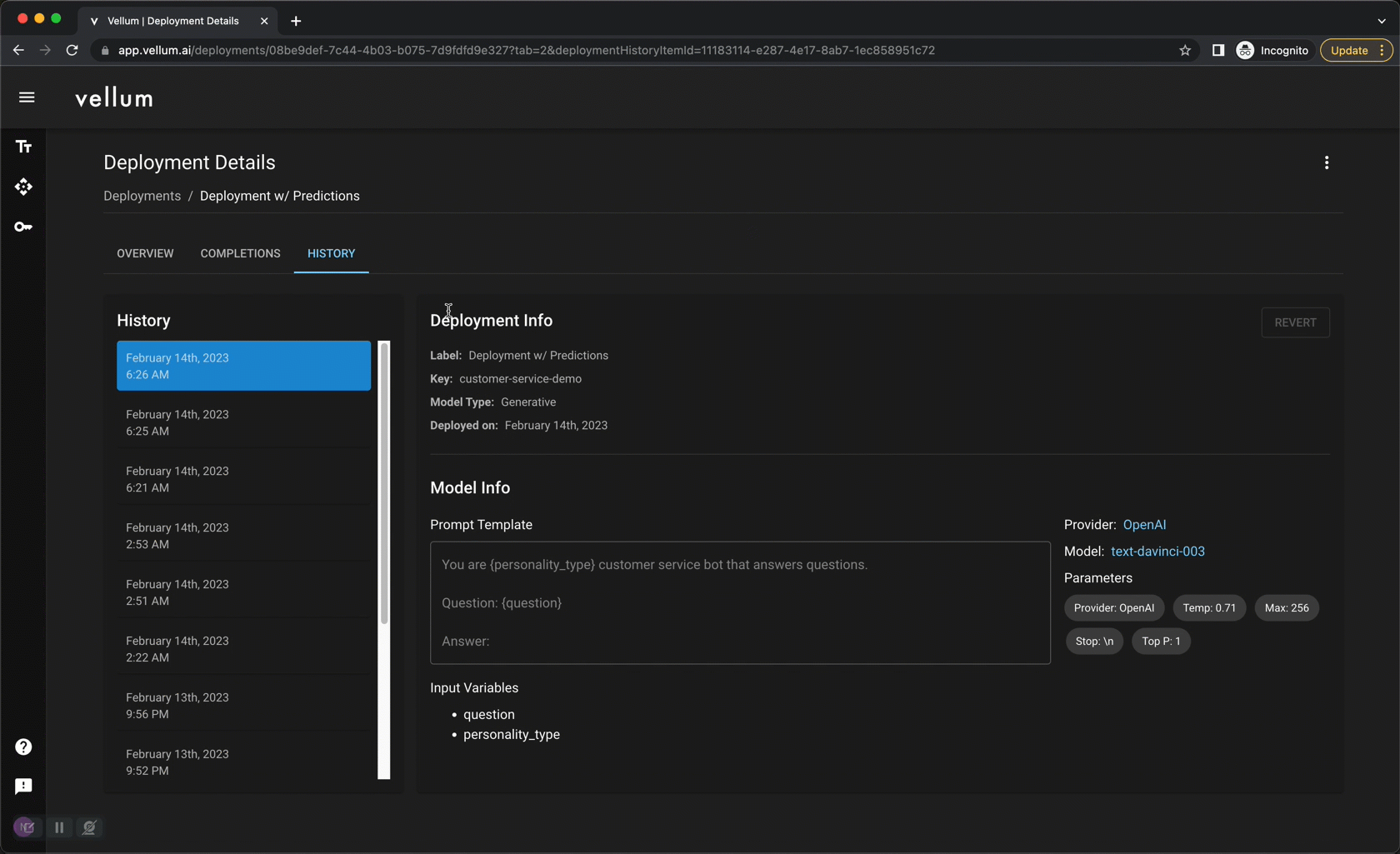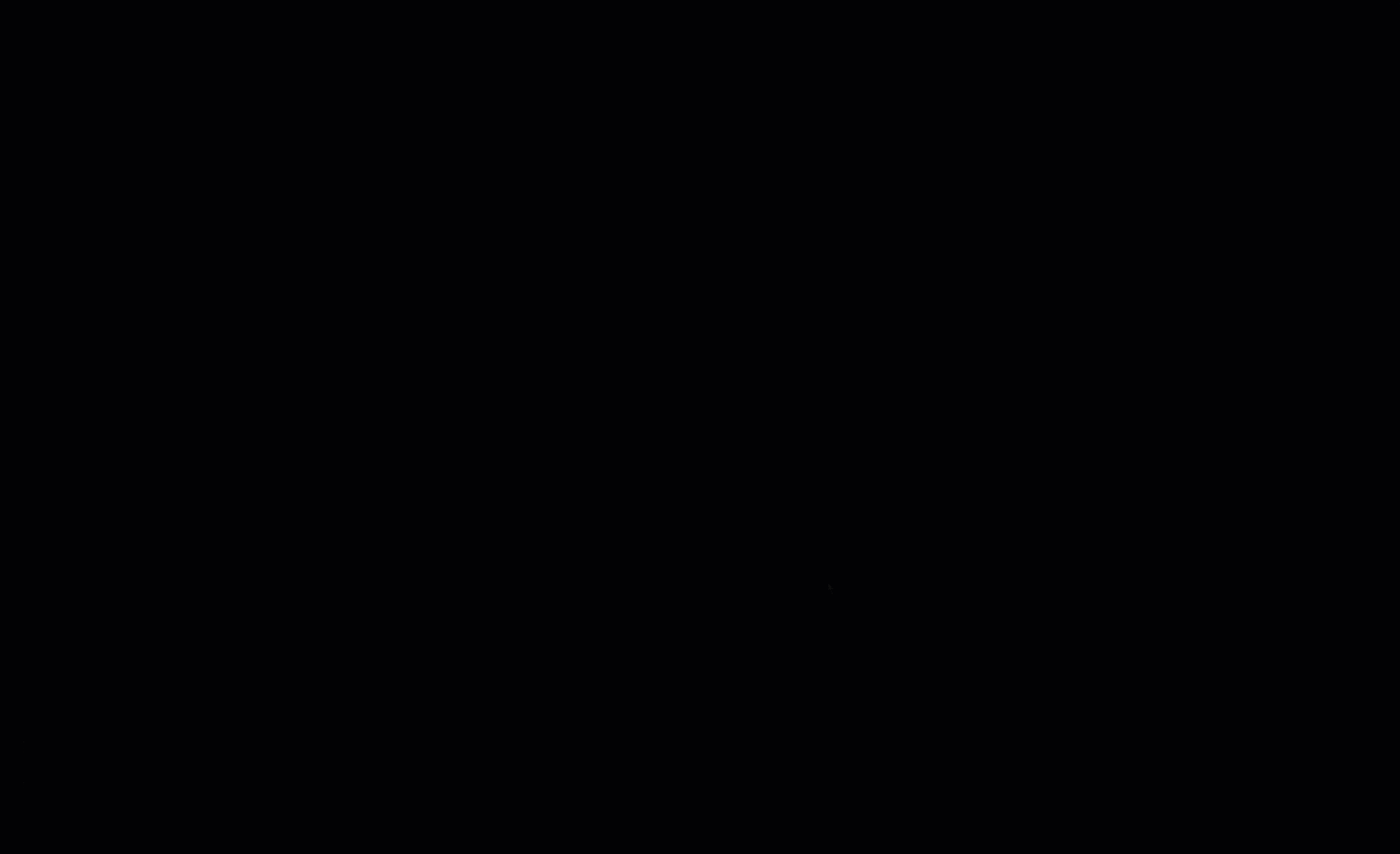
Vellum Playground: Super powers for prompt engineers
Create one “sandbox” per LLM use-case. In each, you can try as many prompt variants as you like across as many test cases as you wish. These prompt variants may differ in their text, underlying model, model parameters (e.g. “temperature”), and even LLM provider! Each run is saved as a history item and has a permanent url you can use share with teammates and track results.
Vellum Manage: Confidently iterate on models in production
Once you’ve settled on a prompt you like, you “deploy” it through Vellum. Vellum acts as a high-reliability, low-latency proxy layer between you and LLM providers. Every request is captured and persisted in one-place, providing observability into your model’s performance. Because the API interface doesn’t change, you can update your prompt (and even the underlying LLM provider!) without making any code changes. Previously made requests can be replayed against proposed changes to gain confidence prior to updating a deployment. All updates are version-controlled and you can revert to prior versions at any time.
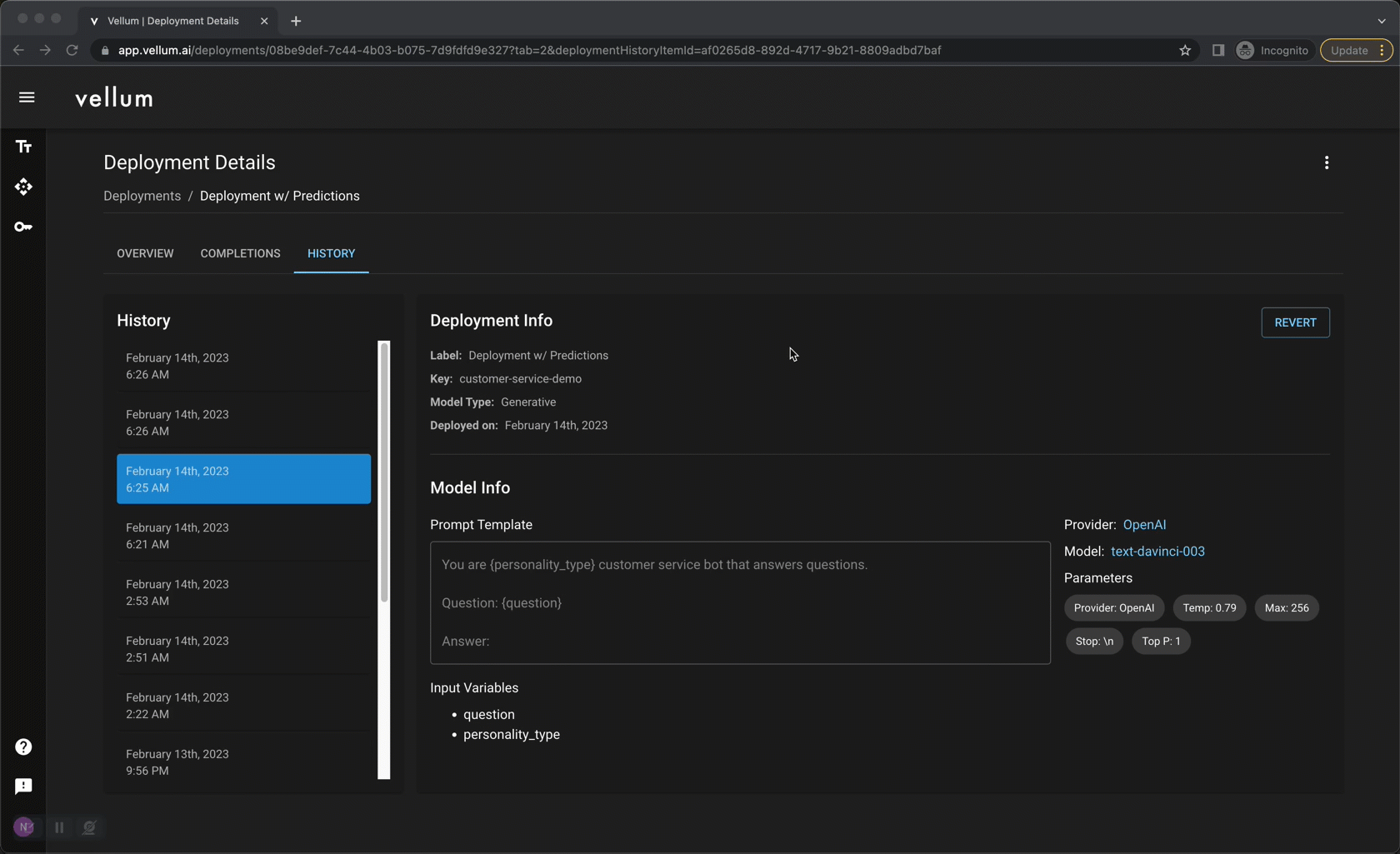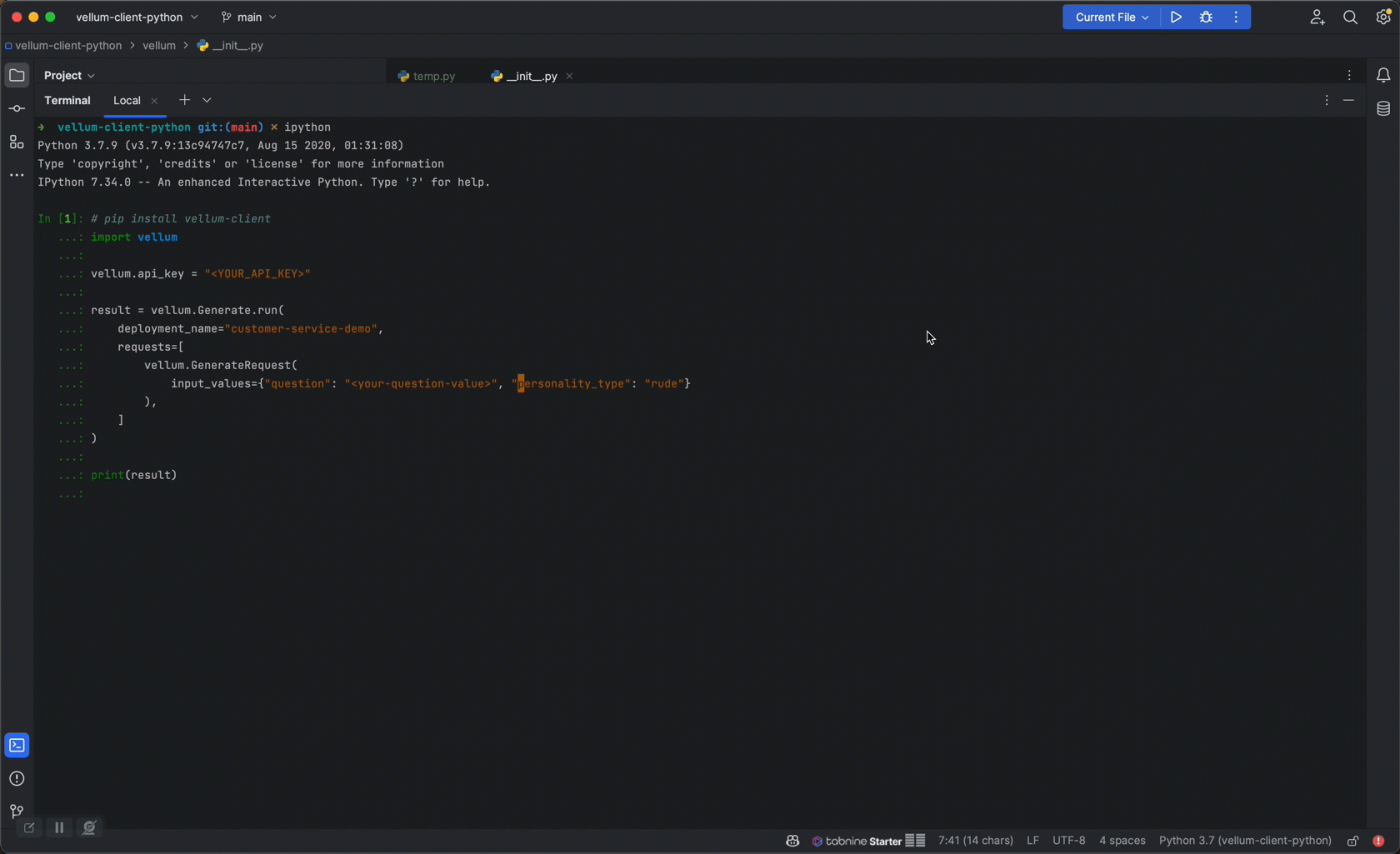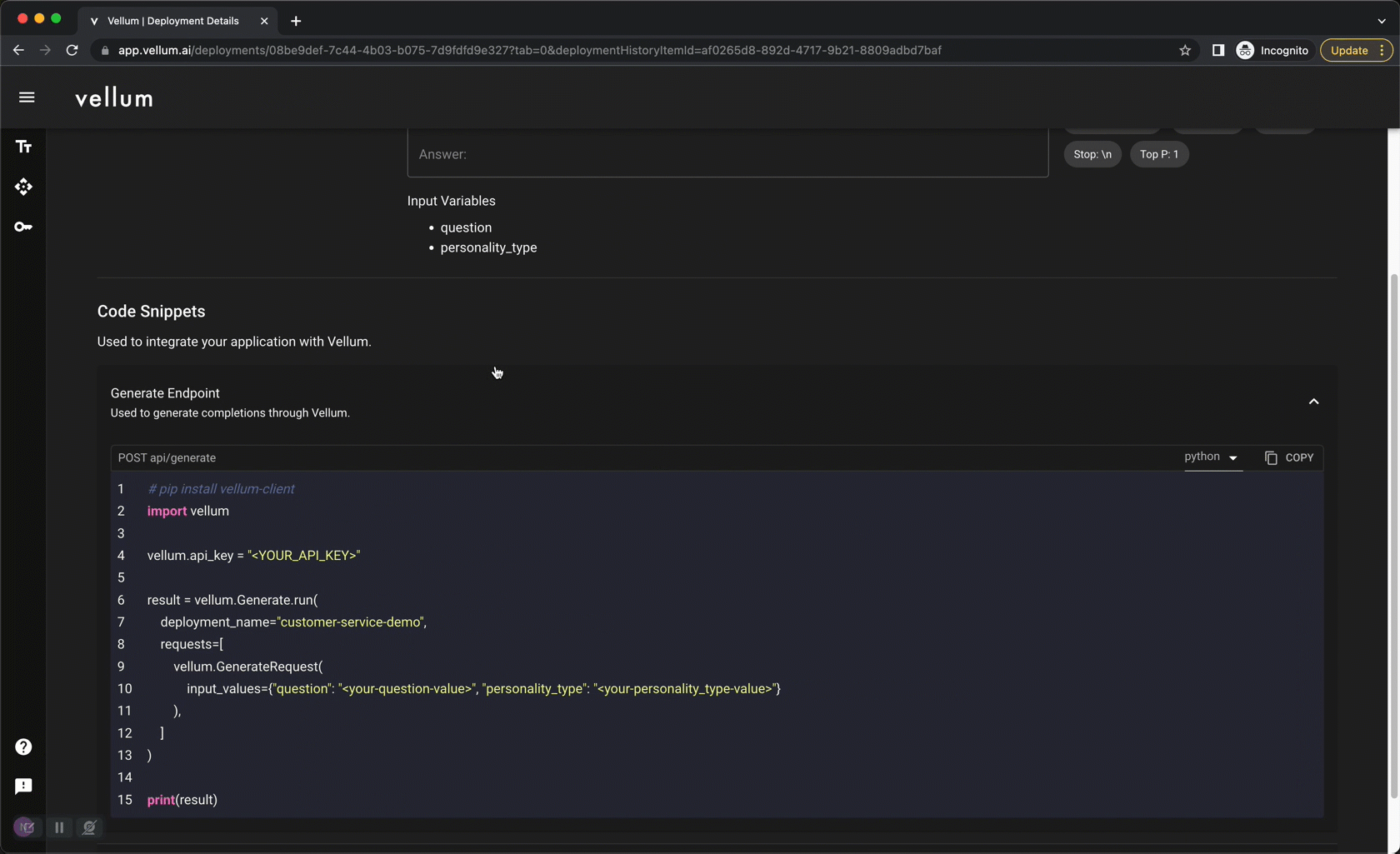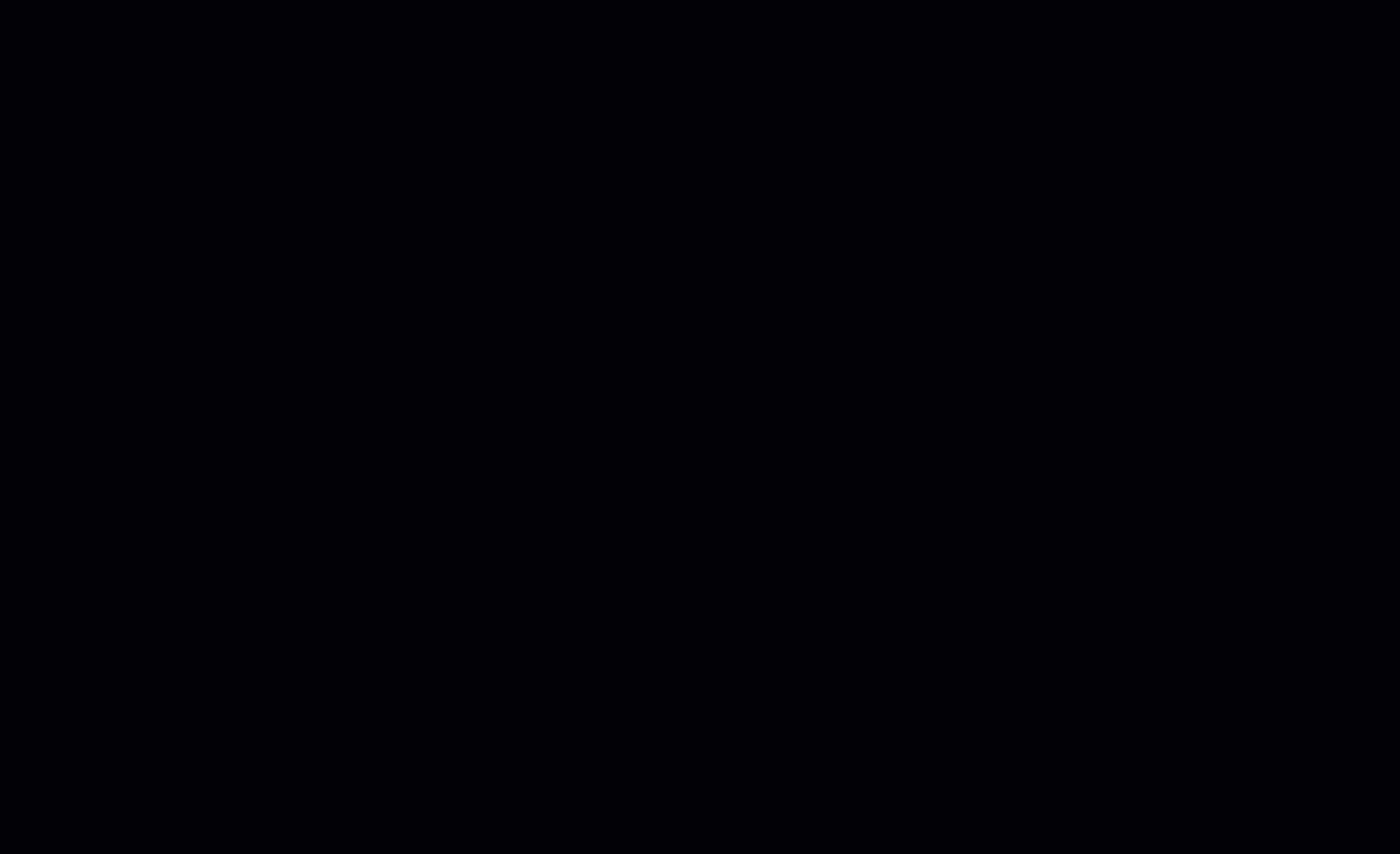
Vellum Optimize: Continuously fine-tune to improve quality and lower cost
Once you’ve collected data in production for some time through Vellum Manage, these input/output pairs (minimum 100, but depends on the use case), can be used to fine-tune your own proprietary models for better quality, lower cost, or lower latency. Your data and your models become a powerful competitive moat. Vellum periodically runs model evaluation jobs in the background to see if we can find a different model that works even better for your use case. If one is identified, you can swap models under-the-hood – no code changes needed!
P.S: If you’re curious, we recently published a blog where you can learn more about the benefits of fine-tuning and how to do it. Check it out here.
Trusted by companies on the bleeding edge of AI

Our ask
- Visit our website to learn more, request early access if any of these problems resonate with you!
- Spread the word! Share this post if you know of others looking to build applications using LLMs who would likely benefit from our platform
- If you’re thinking about using LLMs and would like to discuss your use-case with us, please reach out through our website!