DAGWorks: Avoid Machine Learning Pipeline horror stories 😱
From creation to maintenance, DAGWorks is building a more human capital efficient way for Data Science teams to build and own Machine Learning Pipelines.
👋 Hi, Stefan & Elijah here from DAGWorks.

TL;DR:
(1) At DAGWorks Inc. our goal is to make Machine Learning (ML) initiatives more human capital efficient. (2) Our solution is an open source SaaS platform for Data Science teams to build and maintain model pipelines, plugging into as much of your existing MLOps and data infrastructure as you want. (3) Star our open source project Hamilton on github and get started with it via tryhamilton.dev.
❌ The Problem:
Ask a Data Scientist whether they like inheriting someone else’s ML pipelines. 99% of the time, they’ll say no. Why? Getting ML to production is easy when you’re small, but when your team and codebase start to grow, maintaining these pipelines becomes challenging:
- 😕 understanding code you didn’t write
- 🐛 debugging production issues
- 🏗️ migrating to new infrastructure
- 🥼 handling personnel changes
This causes teams to spend far more time keeping existing ML pipelines afloat than innovating and driving their business forward.
To get out of/avoid such a mess, you need a high (and expensive) software engineering skill set, but for many that’s not an option. In our experience, this phenomenon is the biggest blocker to leveraging machine learning in your business as it grows.
✨ Our Solution
(1) We leverage our open source project Hamilton, which is an opinionated way to write python code (akin to what DBT did for SQL), that naturally helps teams follow software engineering best practices.
(2) Using the DAGWorks Client on top of Hamilton, we can give you full insight into how your pipelines operate on the DAGWorks Platform, including:
A catalog of functions - feature catalog anyone?
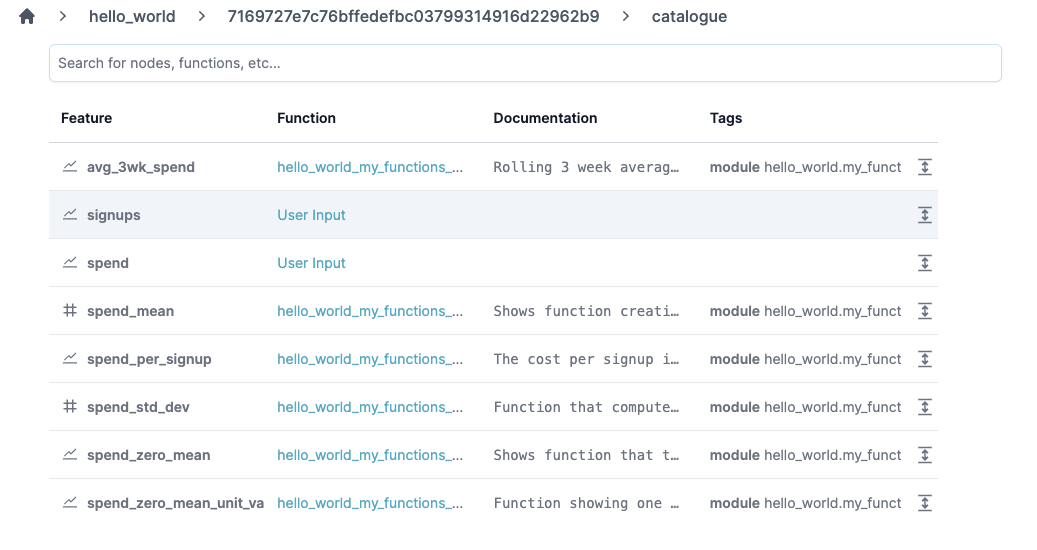
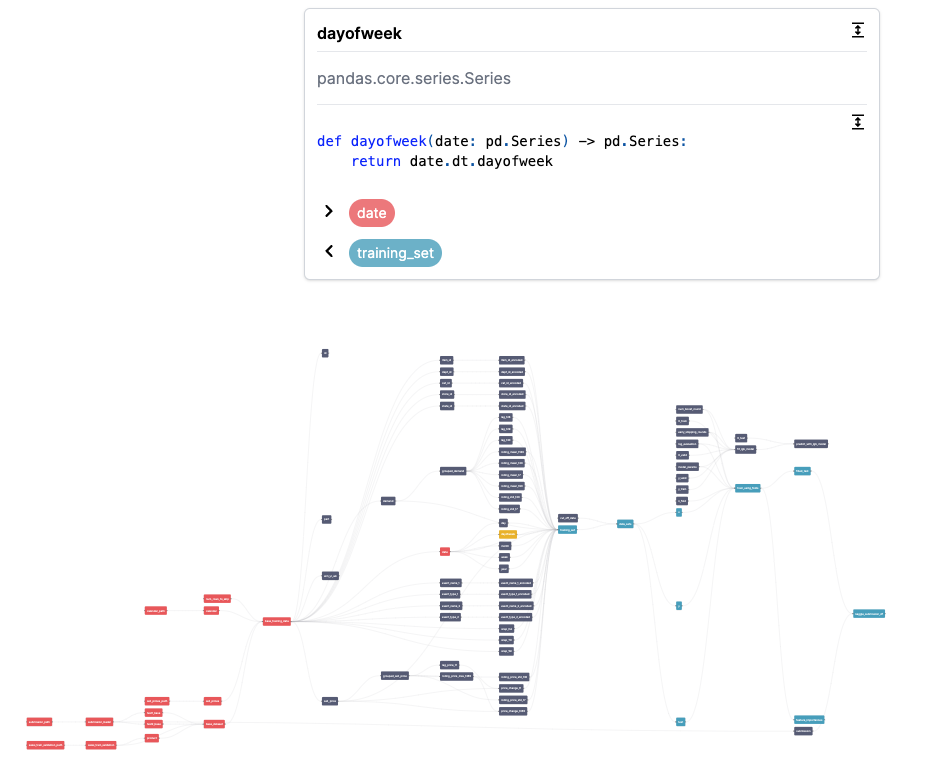
Lineage - see upstream and downstream dependencies:
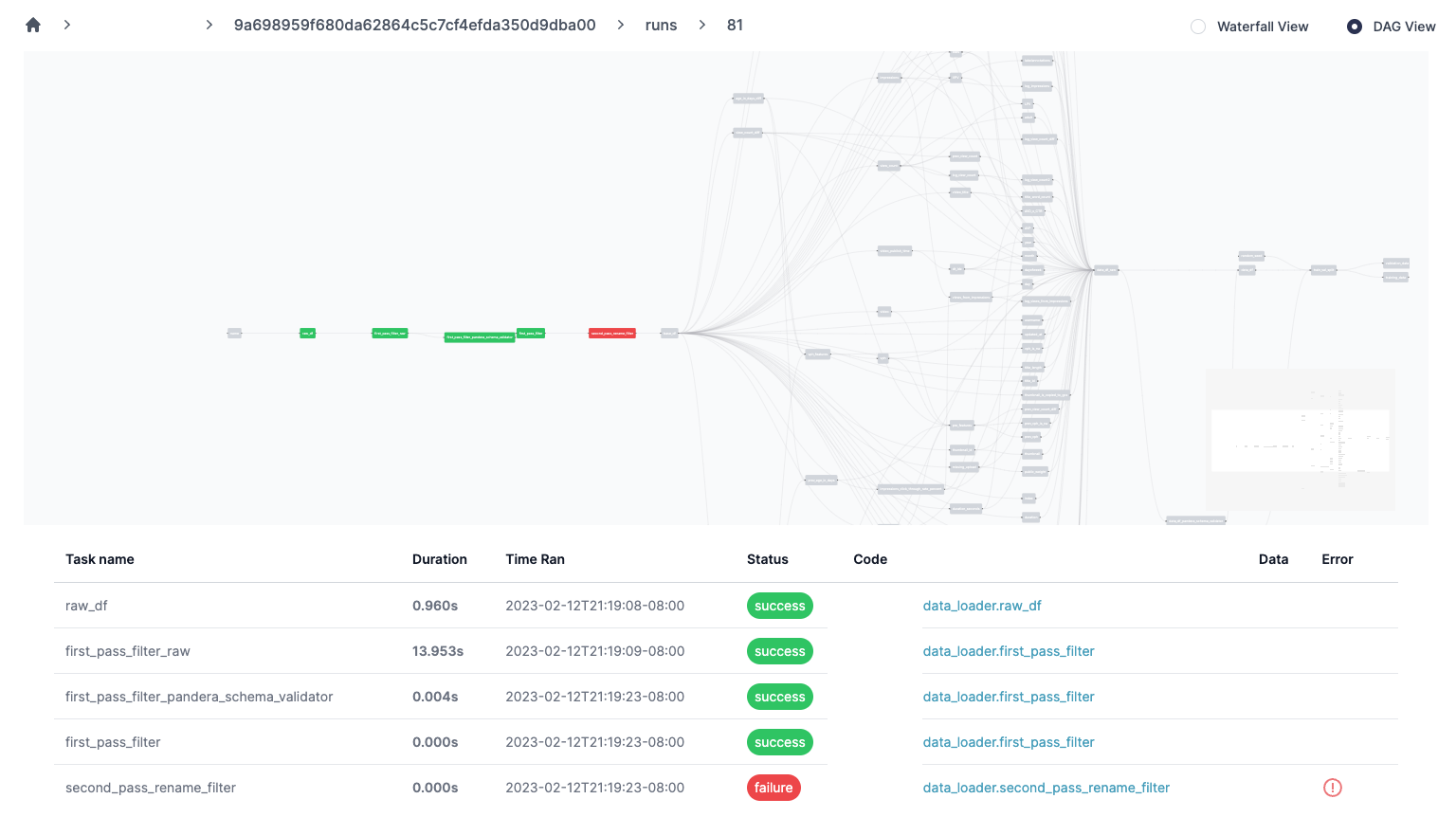
Debugging insights - e.g. know exactly what code failed given an airflow task failure:
And more like data observability, and links with materialized artifacts (like data sources, models, features, etc.).
(3) The DAGWorks Platform becomes your ML Pipeline control plane. Use it to manage integrations with your existing infrastructure, as well as providing any reporting and compliance insights you need.
⚙️ How it works
With Hamilton, users logically express what should happen, which helps avoid vendor and infrastructure lock in. Then with the DAGWorks Platform & Client, we make your Hamilton code run on your existing infrastructure, providing out of the box connectors to common systems, and provide insights post execution. By building on a solid foundation that clearly decouples concerns, we can avoid the problems that plague traditional ML Pipelines. This enables Data Science teams to move faster and do more themselves, making ML projects more human capital efficient.
👪 Founding Team
Stefan and Elijah worked together at Stitch Fix where they built the self-service ML Platform for over 100 data scientists. They learned firsthand the troubles that occur building and maintaining ML Pipelines over a diverse set of modeling disciplines. Their work has been recognized by industry and included in books, newsletters, and was even the topic of a lecture at Stanford. Previously Stefan built data and ML systems at Nextdoor and LinkedIn and graduated from the Stanford CS Masters program with a Distinction in Research. Elijah built tools for quants at Two Sigma and studied Math and CS at Brown.
🙏 Asks
- Start with Hamilton open source today!
- ⭐️ Star Hamilton on Github! Download it from PyPI.
- Checkout out www.tryhamilton.dev for an in browser overview of Hamilton. A common use case is to start using it for feature engineering.
- Don’t know how to leverage Hamilton – book time and we’ll walk you through it!
- We’re looking for more leads to larger organizations that have ML Pipeline struggles, in particular if they have compliance/auditing needs for them. Know someone, or perhaps you’re the right person? Please email us - founders@dagworks.io or book 15 minutes here.
- We’re still currently in closed beta for the DAGWorks Platform, but you can sign up for early access via www.dagworks.io.
- Follow us on Twitter for updates: