Flower: Train AI on distributed data
Meet 🌼 Flower, the Friendly Federated Learning Framework
Hi everyone - we're Daniel, Taner, and Nic, and we're excited to introduce Flower:
TL;DR 🌼 Flower is an open-source framework for training AI on distributed data using federated learning. Companies like Brave, Banking Circle, and Nokia use us to improve their models with sensitive data that they could not leverage before.
→ Before you continue: give us a star on GitHub ⭐️
Problem: What's holding AI back?
Almost all of the AI breakthroughs you know of — from ChatGPT and Google Translate to DALL·E and Stable Diffusion — were trained with public data available on the web. Conventional machine learning needs all data collected in a central place, the motto has always been to “move the data to the computation.” This approach has given us some impressive results, but we are seeing those advances struggle to make their way into other important areas, like healthcare.
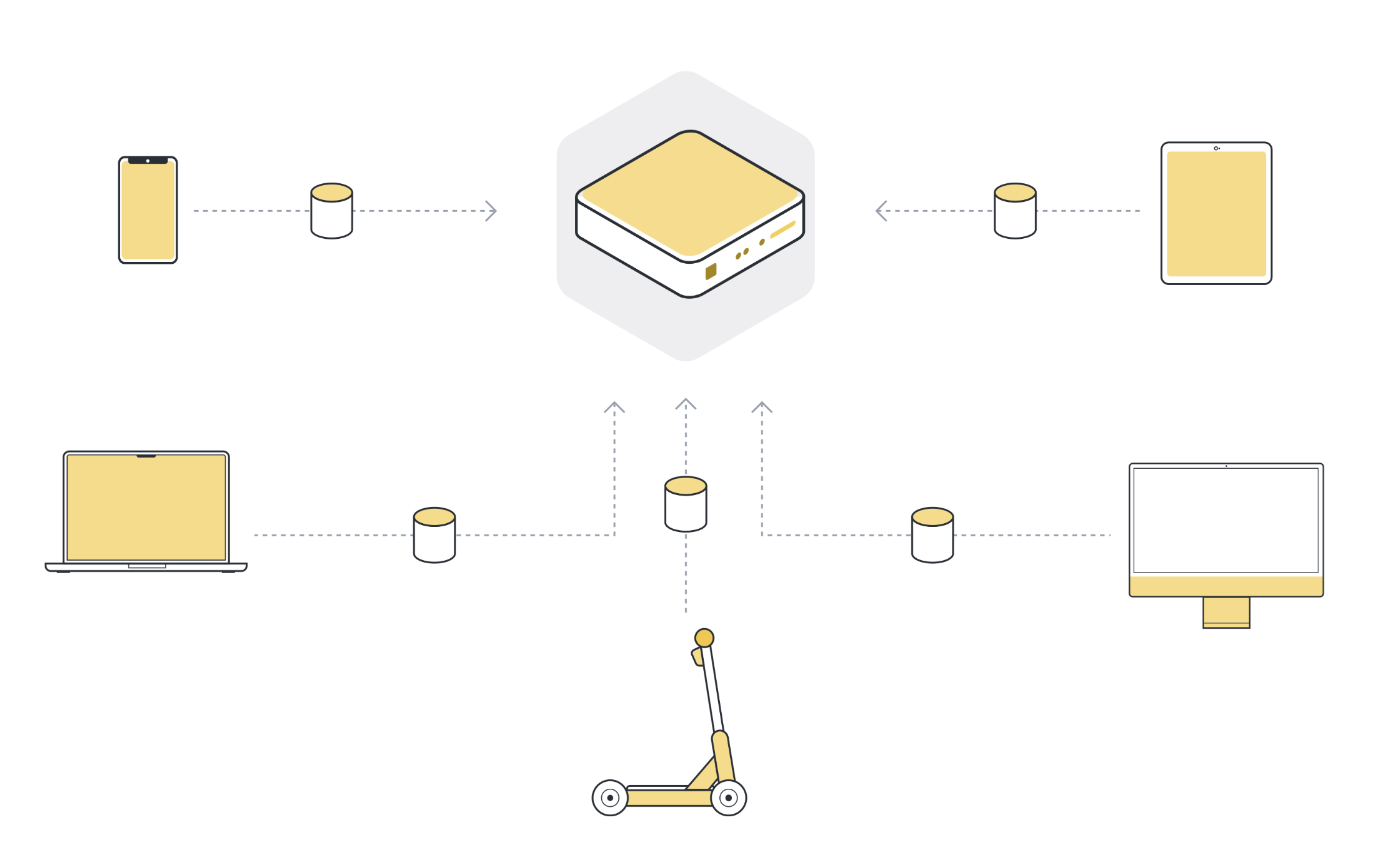
Why is that? The reason is simple: most data is sensitive and distributed across organizational silos or user devices. It cannot be collected in a central place, which prevents us from training state-of-the-art models for many important use cases:
- 👩🎨 Generative AI: Many scenarios require sensitive data that users or organizations are reluctant to upload to the cloud.
- ❤️🩹 Healthcare: We have excellent AI model architectures, and we could train cancer detection models better than any doctor in the world, but no single organization has enough data
- 🏦 Finance: Preventing financial fraud is hard because individual banks face data regulations, and in isolation, they don't have enough fraud cases to train good models
- 🏎️ Automotive: Autonomous driving could transform our lives, but, again, individual car makers struggle to gather the data to cover the long tail of possible edge cases
- 💻 Personal computing: Users don't want certain kinds of data to be stored in the cloud, hence the recent success of privacy-enhancing alternatives like the Signal messenger or the Brave browser
- 📚 Foundation models: The more and the more diverse data we have to train foundation models, the better they generalize. But again, most data is sensitive and thus can't be incorporated as these models continue to grow bigger and need more information.
Solution: Federated learning (and other PETs)
Federated learning can train AI models on distributed and sensitive data by moving the training to the data (instead of moving the data to the training); it just collects the insights from the learning process, and the data stays where it is. And because the data never moves, we can train AI on sensitive data spread across organizational silos or user devices to improve models with data that could never be leveraged until now.
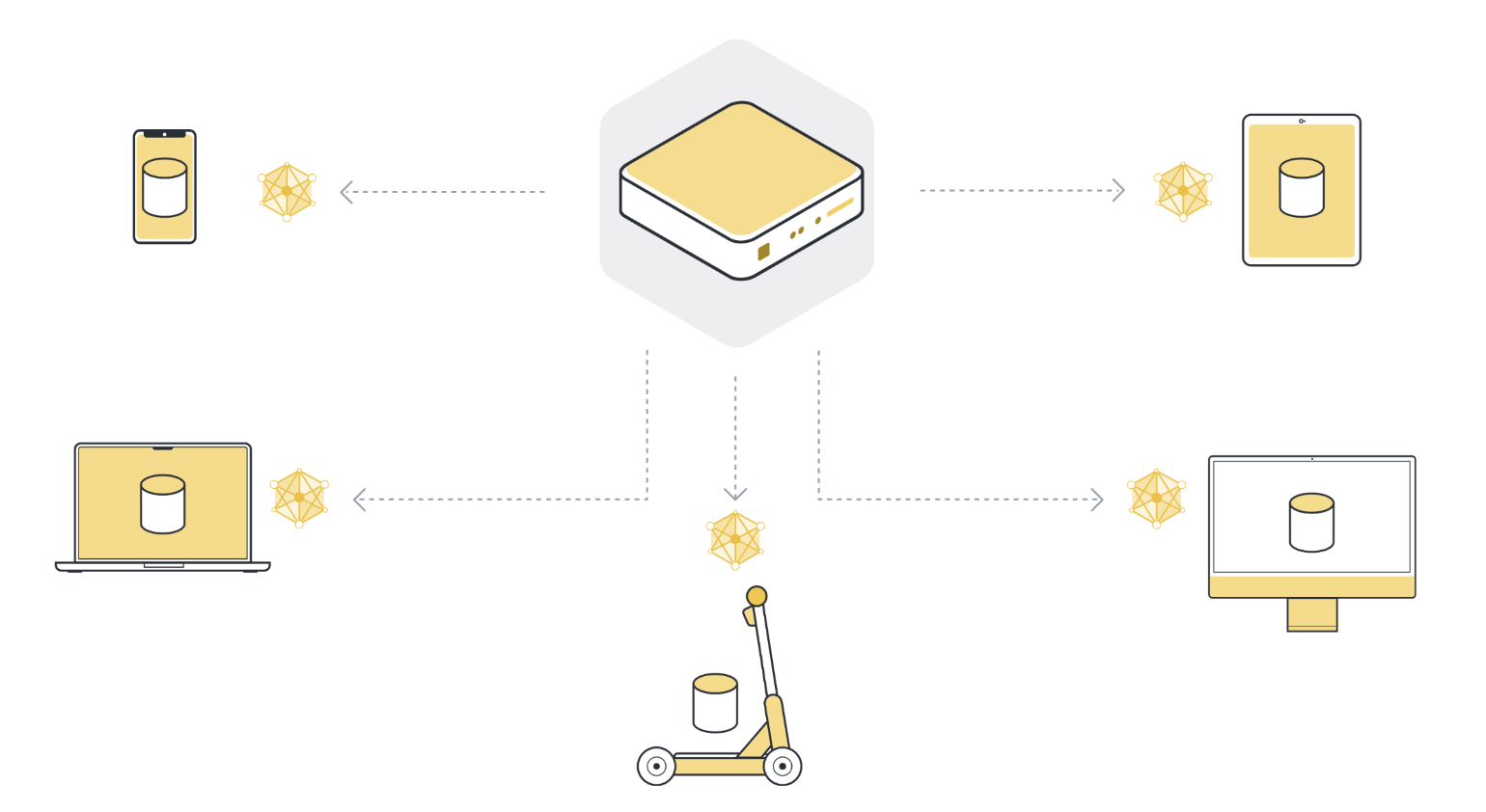
This is, of course, more challenging: we must move AI models to data silos or user devices, train locally, send updated models back, aggregate them, and repeat. Flower provides the open-source infrastructure to easily use federated learning (and other privacy-enhancing technologies - or short: PETs) with all the tools you know and love today - PyTorch, TensorFlow, JAX, Hugging Face, fastai, Weights & Biases - just bring your existing project, and easily “federate” it using Flower.
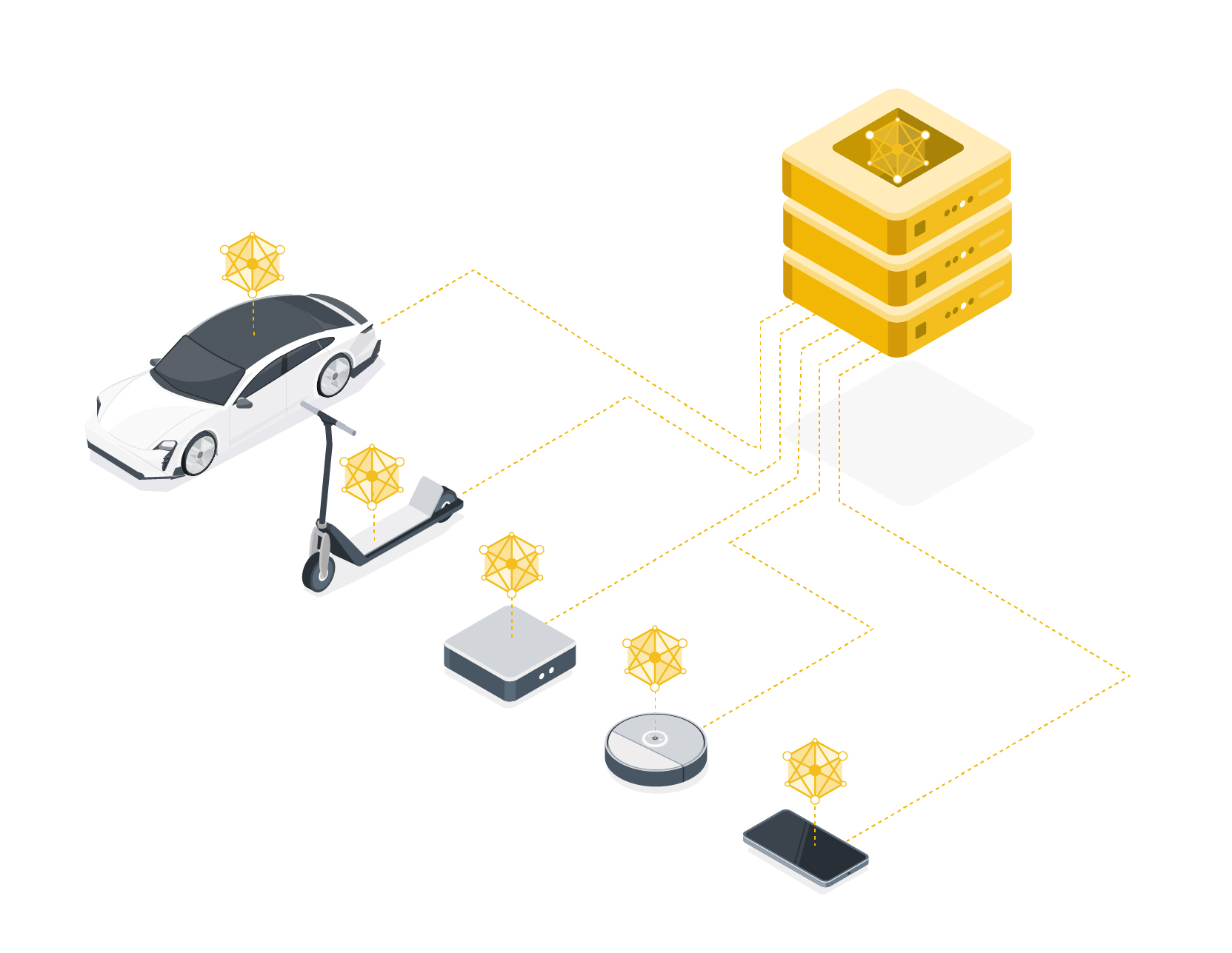
Asks: How can you help?
- Give us a star on GitHub ⭐️ (if you haven't done so already)
- Are you (or someone you know) facing challenges in getting the data you need to train good AI models? We’d love to talk: founders@flower.dev
- Take the tutorial to learn federated learning in 10 minutes (and give us feedback on how to improve it to make it easier to understand → founders@flower.dev)
- Join the Flower community on Slack
- Interested in working with us? Sign up for the Flower Next Pilot Program