Thread - Incident management for large enterprises
We take the best practices from Amazon and Microsoft and make them available to all engineering organizations.
Hi everyone! We’re Yuheng, Akeem, and Harsha, the co-founders of Thread.
tldr: Thread is incident management for large enterprises. We take the best practices from Amazon and Microsoft and make them available to all engineering organizations.
Problem ❌:
Incidents are the most stressful part of any live production service, and engineers are often ill-prepared for dealing with them… especially in large enterprises. As enterprises move to the cloud and microservice architecture, embrace remote work, and pick up increasingly more tooling for incidents, engineers face growing difficulty identifying and resolving complex system issues.
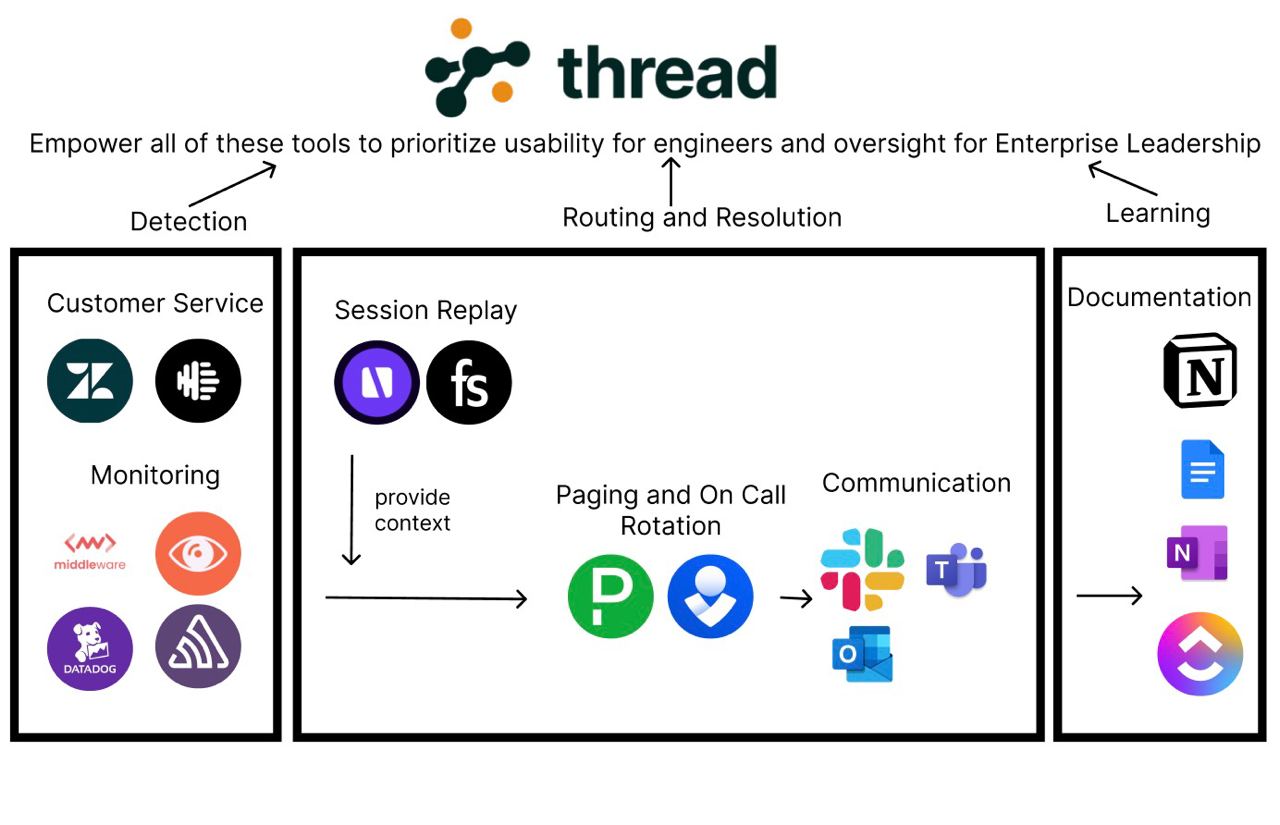
- APMs, such as Datadog and New Relic, overwhelm engineers with data and lack contextual information, making problem-solving a challenge.
- Customer support help desks, like Zendesk, often provide inadequate information when creating tickets, leading to a frustrating cycle of questions for engineers.
- Alerting and ITSM tools, such as Pagerduty and ServiceNow, alert engineering teams but often lack the necessary context for efficient issue resolution.
Not to mention, leadership still lacks visibility into incident details and progression.
It's like trying to solve a puzzle with missing pieces and no picture on the box.
Solution 💡:
The gold standard for incident management workflows is straightforward to describe, but it is incredibly difficult to implement in practice, especially at enterprise scale.
The four pillars are:
Detection: identifying the bug using either a monitoring tool or a customer service tool
Routing: getting the ticket to the right person that can solve the issue, using paging tools and communication tools
Resolution: using context-providing tools like session replays and streamlined data providers to help solve the issue
Learning: identifying the root cause of the issue and generating future workflows to more adeptly solve the problem (or prevent it from happening again)
Enter Thread:
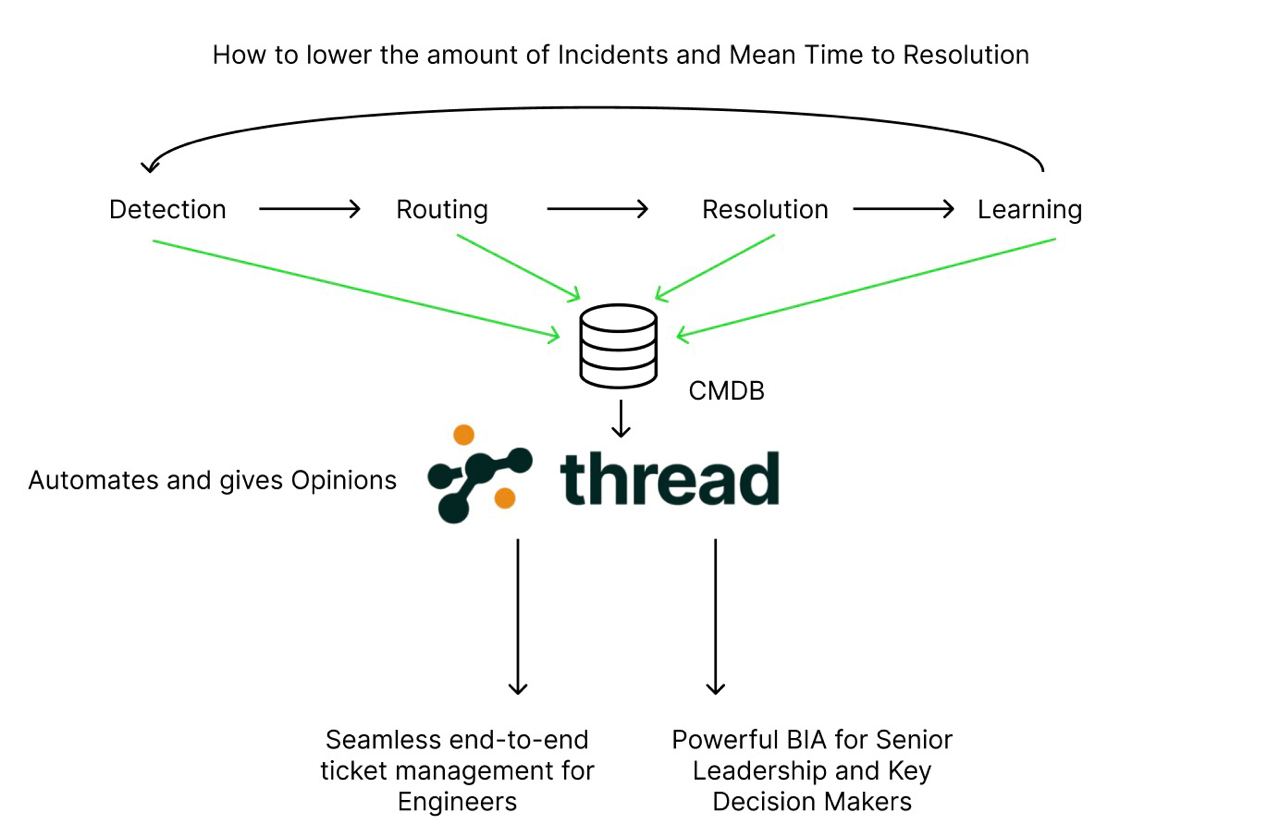
Thread offers engineers a customized configuration management database with runbooks, past tickets, monitoring data, and recommended actions for diagnosing and resolving incidents.
We also provide real-time updates and summaries to leadership and stakeholders during critical incidents, identifying bottlenecks in workflows to prevent future issues.
Why settle for a single tool that might not fit all your needs? Our platform allows teams to bring in their favorite tools to create a tailor-made solution.
Why us?
We’re 3 ex-Microsoft/Amazon engineers who built these tools and processes on our respective teams (Microsoft Store and Prime Video). We want to take what we learned and build an even better solution for the millions of engineers out there, so no one has to face the existential dread of on-call panic ever again.
Our Ask ❤️:
If you or anyone in your network knows a VP/Director of Engineering at a large enterprise, around fortune 500 level, (bonus points if their org currently uses tools like ServiceNow) who would be open to using a 3rd party tool to improve their incident management, processes, and/or learnings, we’d love an intro.
If you have enterprise-level experience with any of the above tools, we want to hear from you! We're always striving to improve our integrations and bridge any gaps in the incident management process. Share your experiences with us!
Reach out to us at founders@usethread.io! We’d love to chat!