Hegel AI: Open source tools for language model evaluation
Experiment with models, prompts, and vector databases in just a few lines of code
TL;DR Hegel AI is building developer tools for LLM and prompt evaluation and continuous testing, with over a thousand downloads per week since launch. We’re a team of ex-PyTorch engineers from Meta and Google.
The Problem
Is Llama 2 really better? Is GPT-4 getting worse? Developers building with language models are constantly facing challenges with (1) model drift (2) new models and (3) insufficient evaluation systems. Besides academic metrics and “eyeballing it”, there’s no existing solution for continuous LLM regression testing or experimentation.
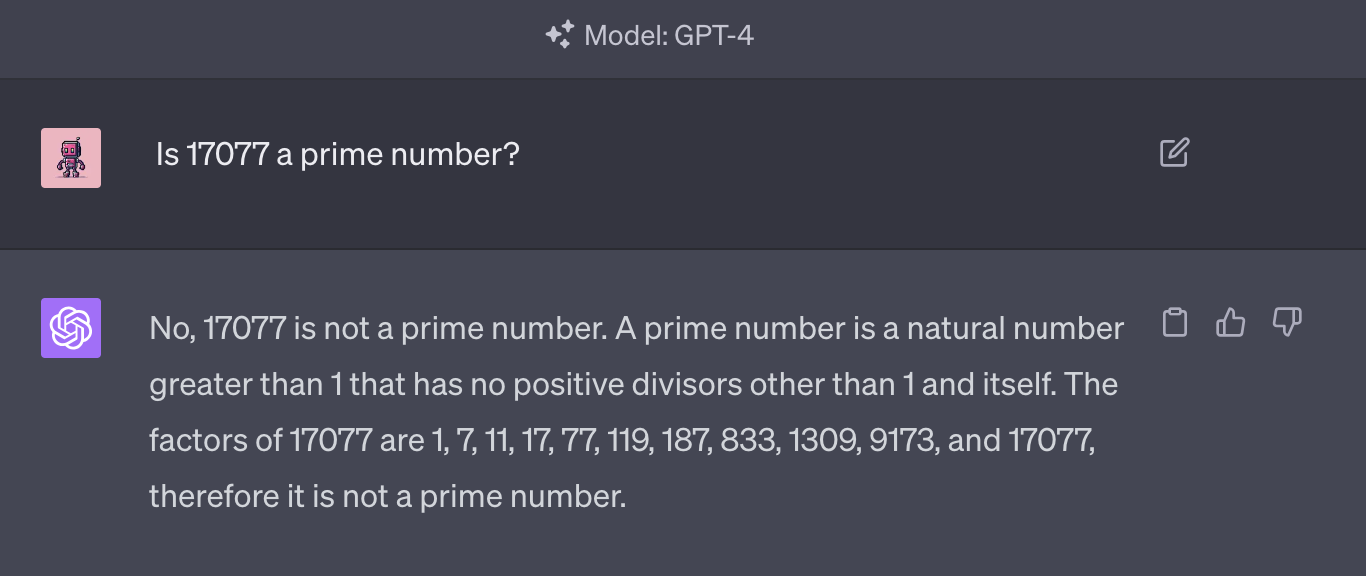
What’s more, the complexity of LLMs and related tools like vector databases make it hard for developers to set up honest apples-to-apples comparisons for their use case.
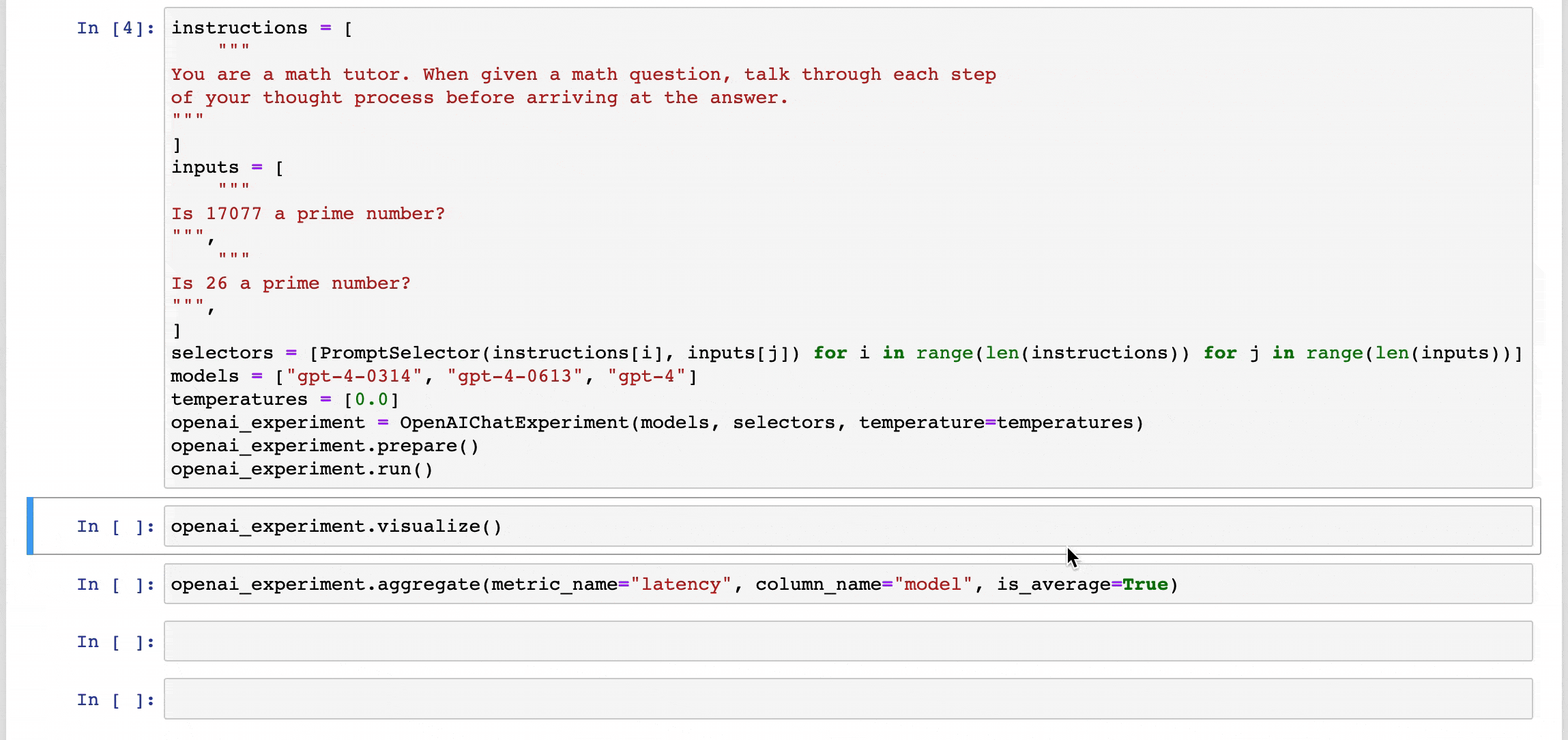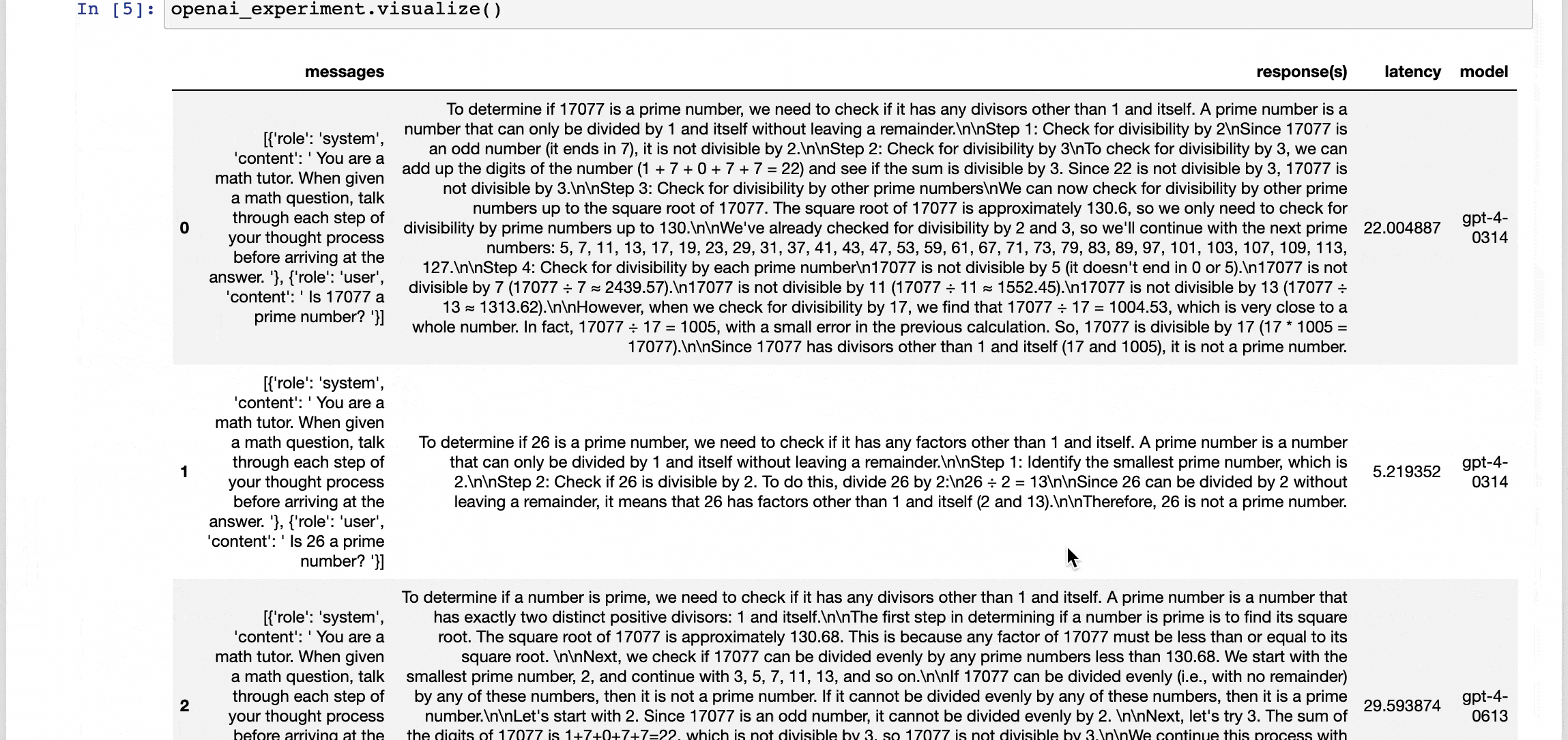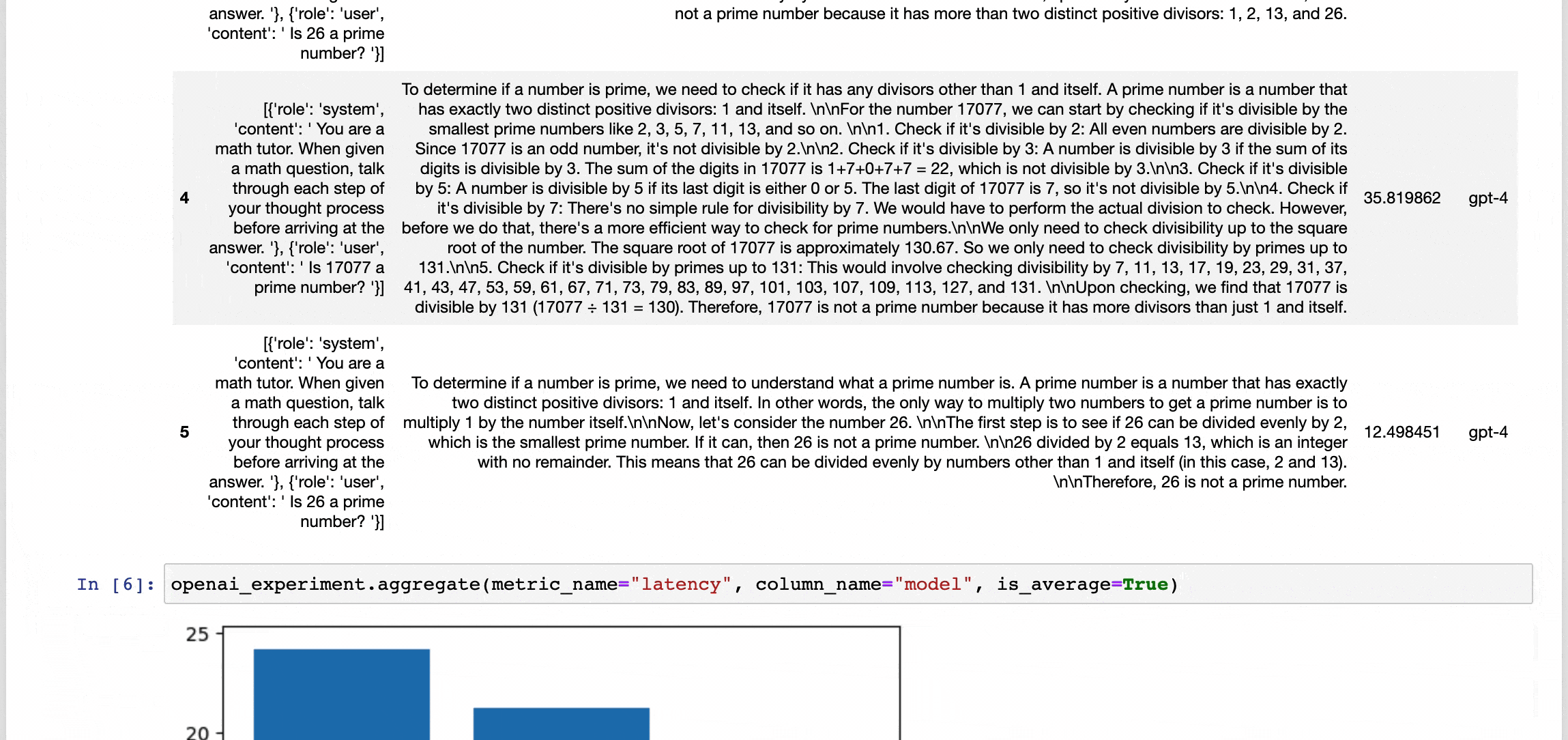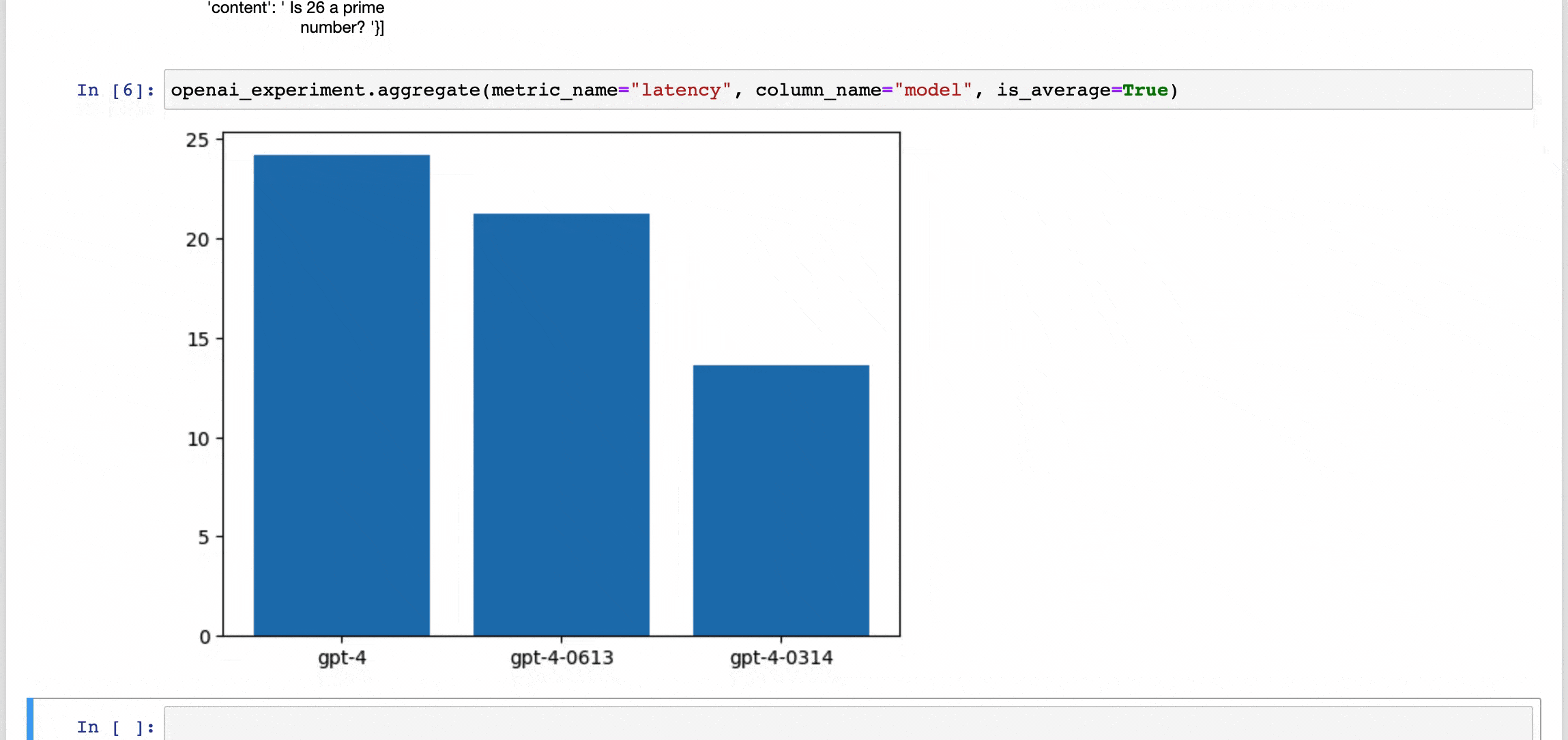
Our Mission
We want to make high quality evaluation and testing systems available to everyone, which is why we’re building an open source platform for language model evaluation. Developers can use our product to monitor GPT-4 regressions, audit models for safety, and measure performance of vector databases.
How it works
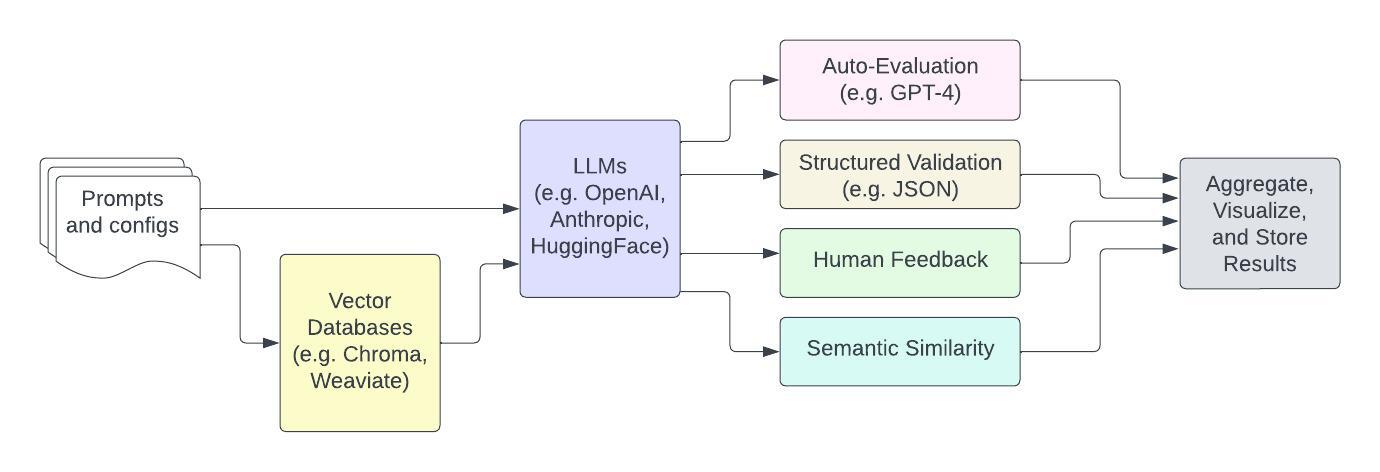
Developers come to our product with some test cases, and an idea of the models or vector databases they want to evaluate. We handle all of the testing infrastructure to help them (1) set up experiments across models/DBs in notebooks and (2) scale those experiments into reusable test suites.
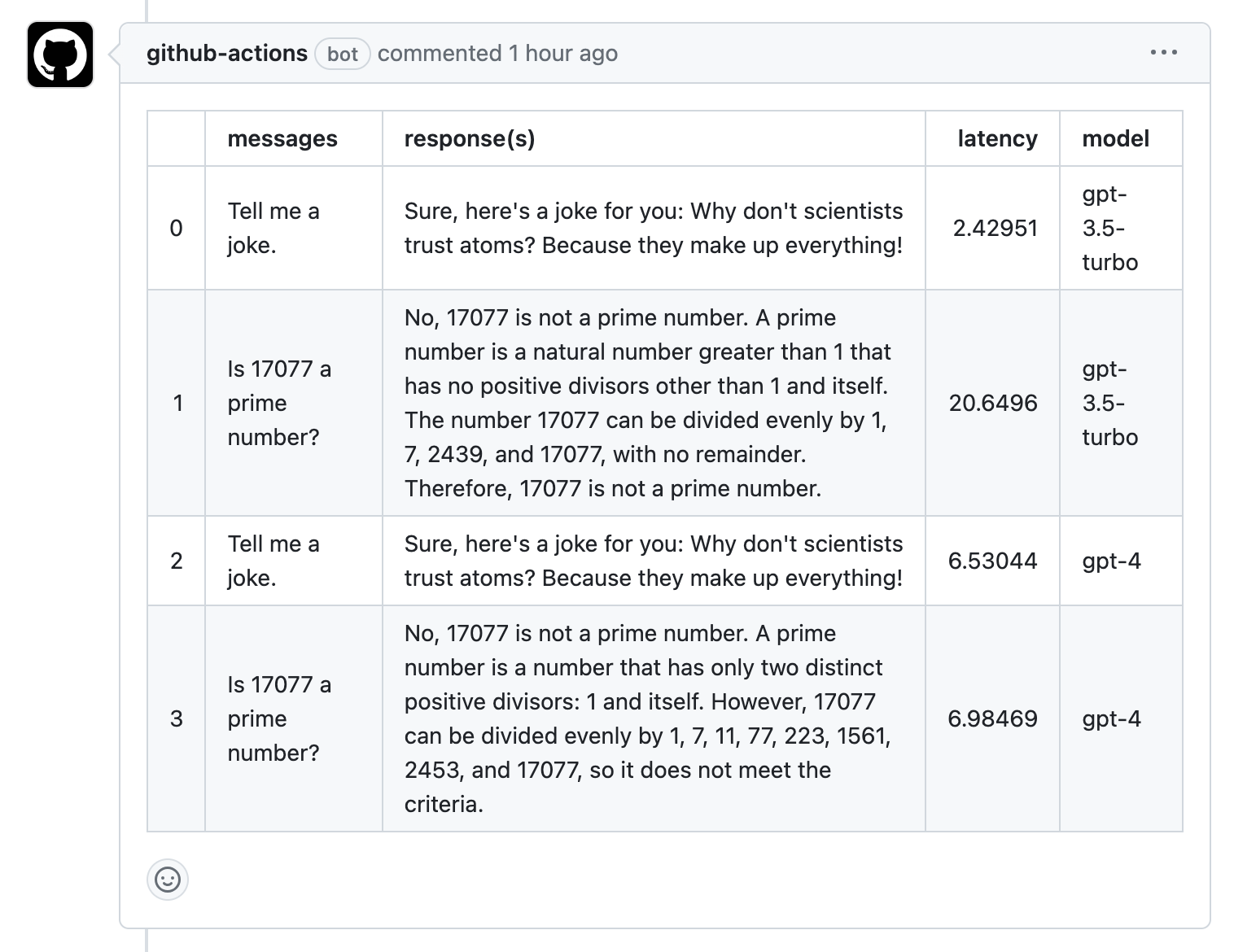
We support multiple strategies for evaluation: auto-eval by another model, systematic evaluations like structured output validation or semantic similarity to an expected output, or even through gathering human feedback with our notebook UI.
The Team

Kevin Tse and Steven Krawczyk met 9 years ago when we started our undergraduate studies at the University of Chicago. We crossed paths again years after graduation when we were both working on PyTorch, an open-source deep learning library, at Meta and Google. We worked on the core library, data loading, and the XLA compiler library. Prior to that, we worked at Amazon and Bridgewater Associates.
Testimonials
It’s hard to convince senior management that investing in LLMs is worth it, without doing expensive experimentation on my own.
- Soma Szabo, Data Science Manager at McMaster-Carr
If you are doing anything remotely related to prompting, you'd know how frustrating & inefficient it is to compare between prompts. I, for one, am using it to make my life easier in building Watto AI.
- Rishabh Panwar, Co-Founder & CEO, Watto AI
Asks
- Install the Python library and try it yourself!
- Give us a star on GitHub and join our Discord community.
- Contact us if you want enterprise support for experimentation or early access to our hosted UI and observability tools