OpenPipe: Convert expensive LLM prompts into fast, cheap fine-tuned models
OpenPipe automatically captures your existing prompts and completions, then uses them to fine-tune a drop-in replacement. The replacement is faster, cheaper and often more accurate than your original prompt.
Hi there! We’re Kyle and David, and we’re building OpenPipe. OpenPipe lets you capture your existing prompts and completions, and then use them to fine-tune a model specific to your use-case. Here’s how the process works:
Problem: General-Purpose LLMs are slow and expensive
Before working on OpenPipe, we each ran into limitations of GPT-3.5 and GPT-4:
- David built an app that required searching Reddit and classifying the results on user-specific dimensions. Because the set of possible results that GPT-3.5 had to classify was so large, each search cost multiple dollars!
- Kyle built (and sold) a startup that involved translating official documents. It was difficult to express the specific requirements that official translations must comply with in a way that GPT-3.5 would reliably follow, but GPT-4 was too slow to provide a good user experience.
We’ve spoken with many other companies and these issues are common. Cost and latency are two major factors blocking production deployment of LLM-backed functionality.
Solution: Replace prompts with auto-deployed fine-tuned models
Small models fine-tuned on a specific prompt are highly performant and can excel at many tasks. They’re particularly good at data extraction and classification, even on tasks that need significant world knowledge.
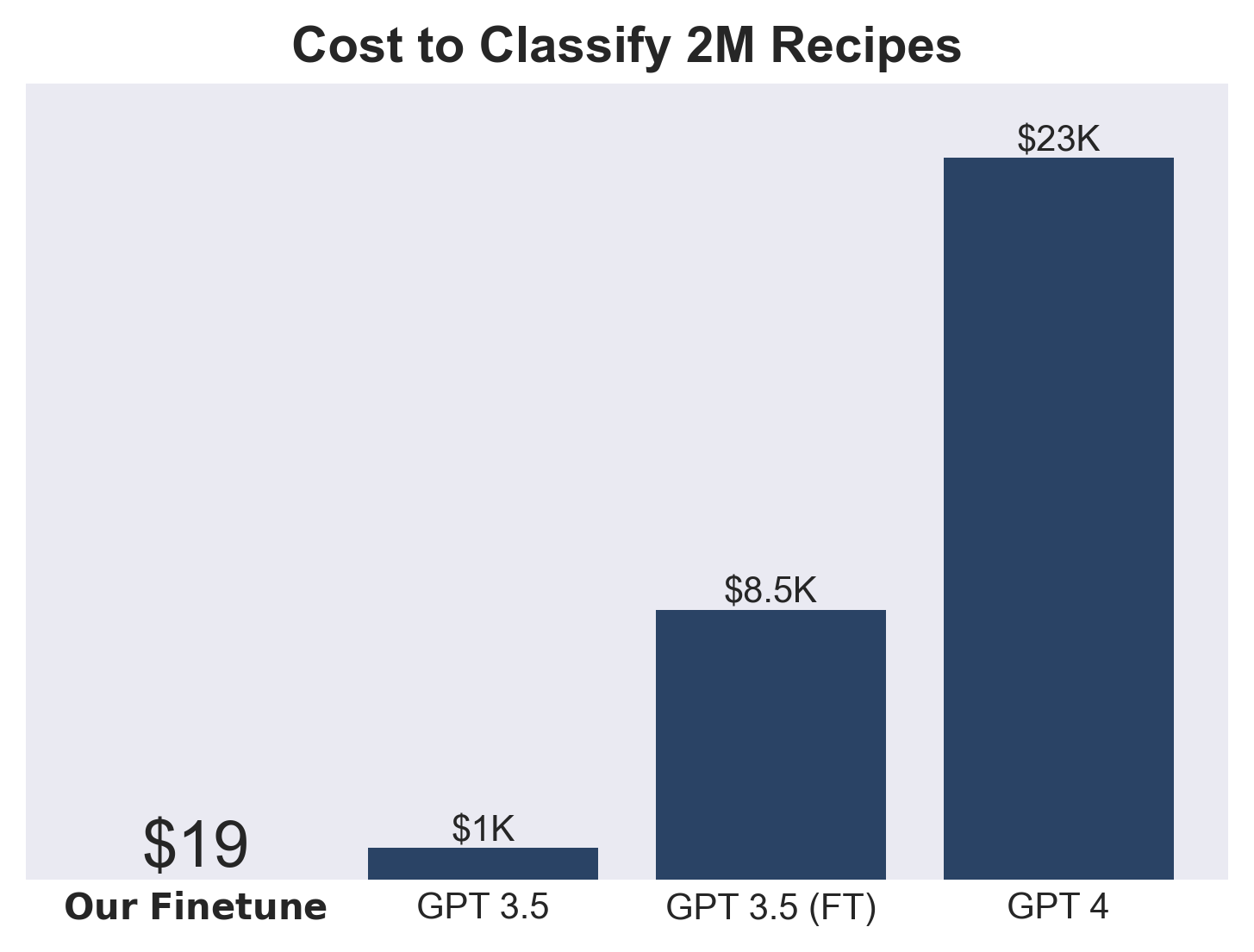
For example, in one project we built to classify recipes, our model was able to determine that a recipe that calls for sautéed mushrooms needs a stovetop, despite not being explicitly trained on that connection. It outperformed GPT-3.5 in classification accuracy and reached 95% of GPT-4’s performance.
And not only does our fine-tuned model outperform GPT-3.5, it costs 50X less to run!
We’ve built infrastructure to make fine-tuning your own model extremely easy. The process works like this:
- Develop a prototype of your LLM-powered feature using GPT-3.5 or 4 like normal.
- Collect prompts and completions over time using our reporting SDK.
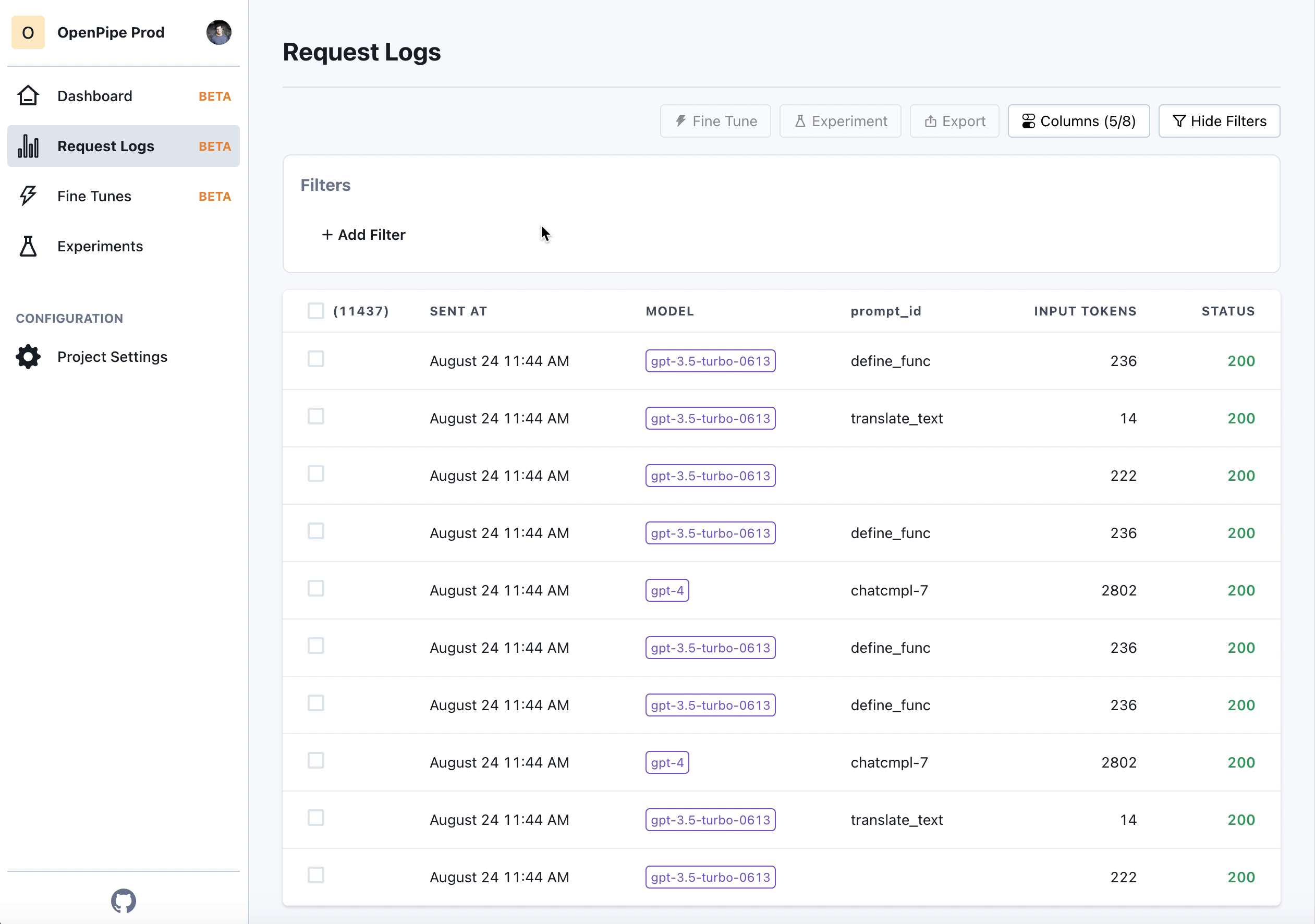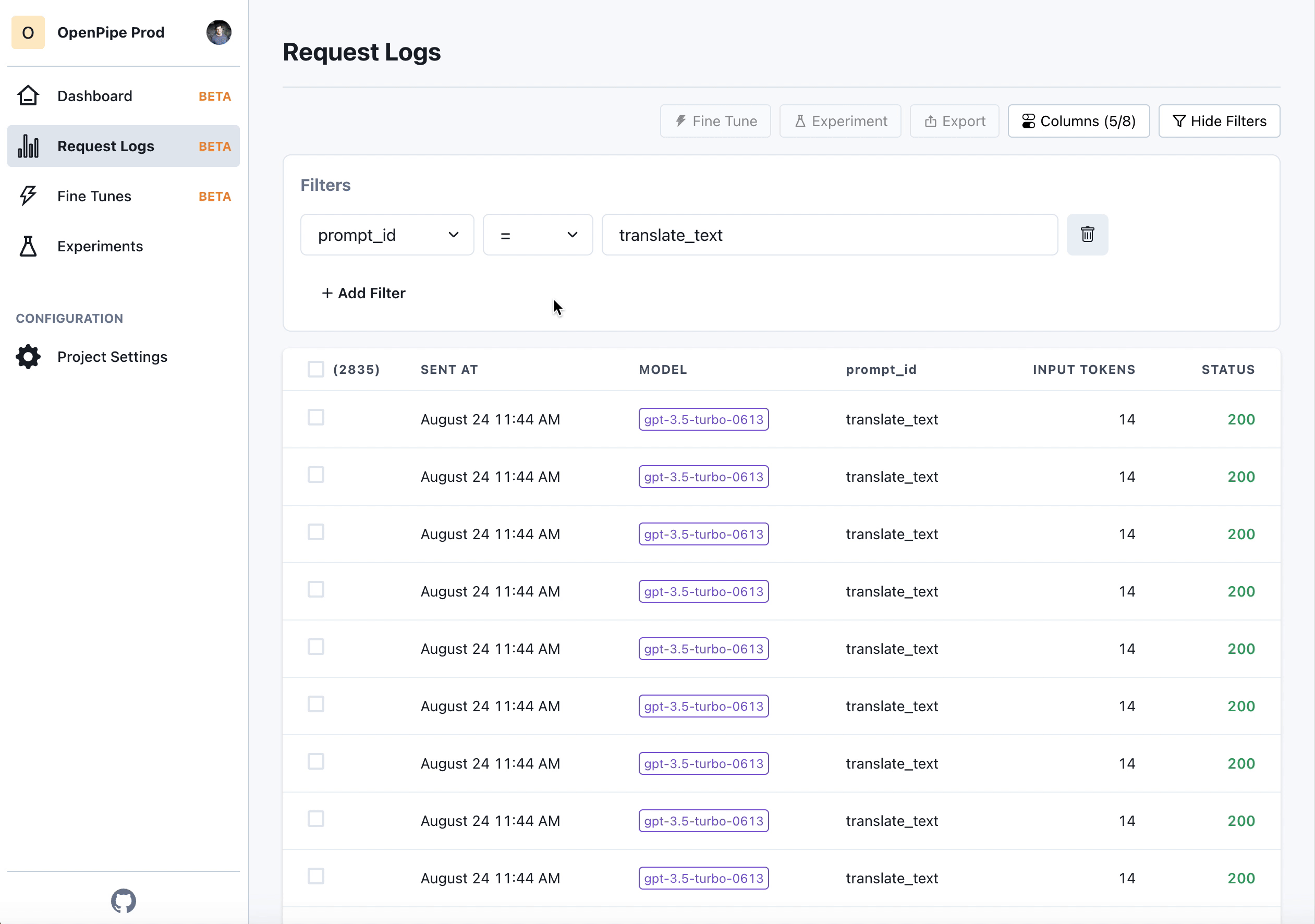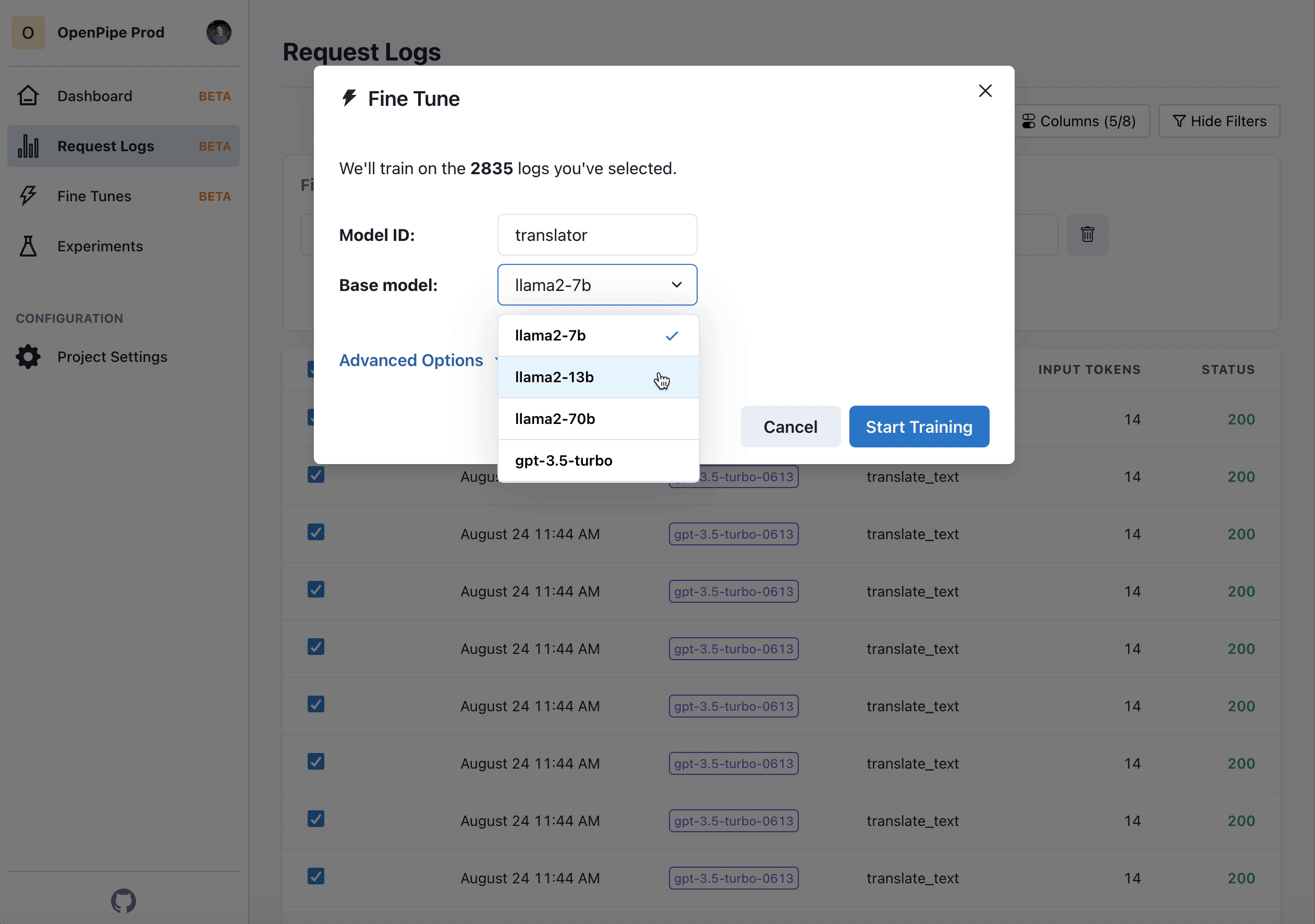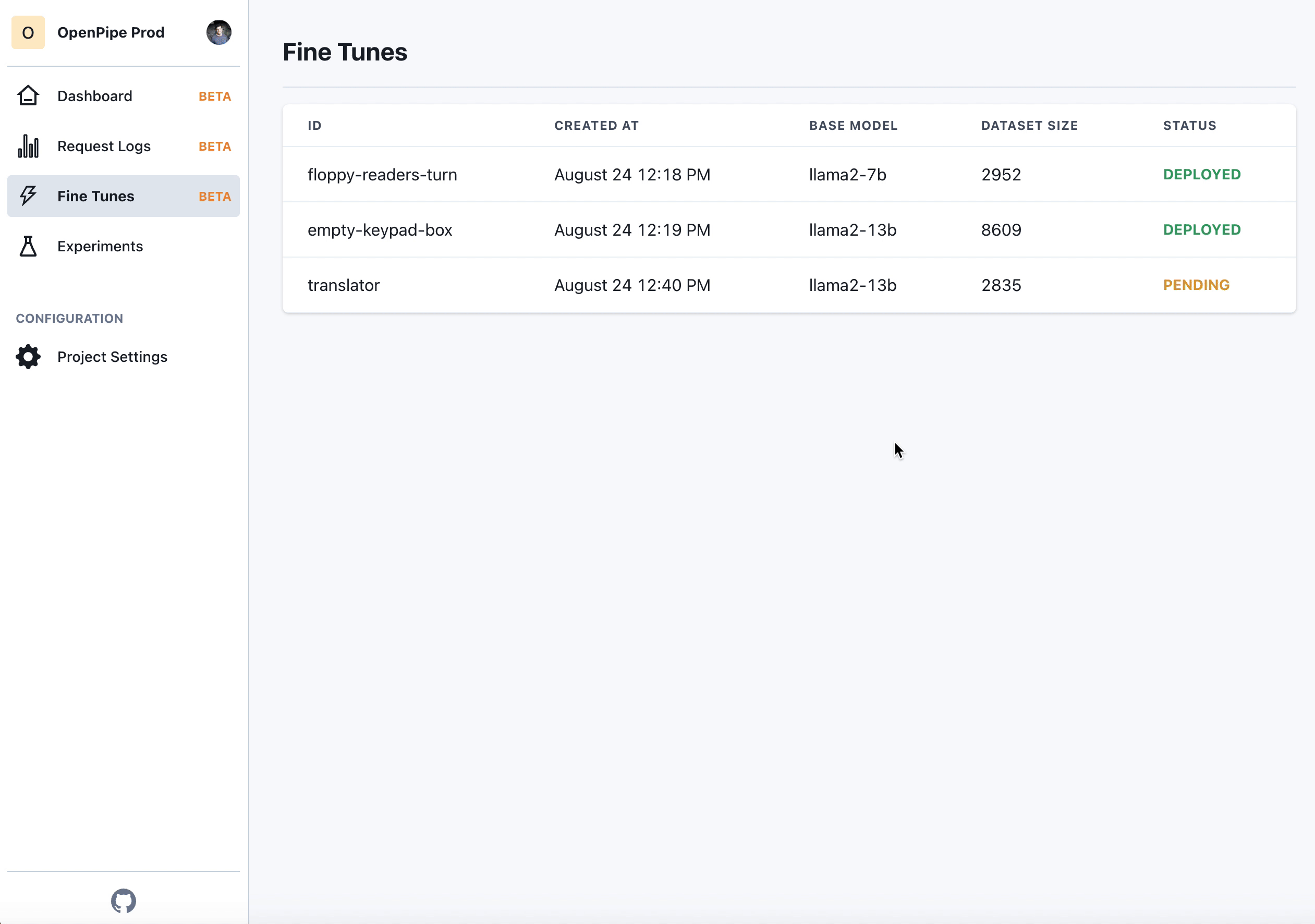
- Once you have a few hundred to a few thousand completions recorded, kick off a training job in our UI.
- A few hours later, your model will be ready. You can either download it and self-host, or host it with us.
- Update your SDK’s URL to point to the new model. Keep your prompts and application code exactly the same — everything will just work!
Our Ask
- If you’re prototyping or rolling out a product that is hurt by the slow responses or high costs of your existing LLM provider, talk to us.
- If you know someone who is prototyping or rolling out AI-based functionality within a large company, link them to this post or just put them in contact with us directly.
You can reach us at founders@openpipe.ai. We’d love to help out if we can!