Superpowered AI - API for Retrieval Augmented Generation 🌐
Superpowered makes it easy to build production-ready LLM applications with access to external knowledge.
TLDR
We’re excited to announce the release of The SuperStack alongside our new Chat endpoint. Now, you can easily deploy conversational LLM applications with knowledge retrieval built-in. Our SuperStack suite of technologies directly targets common RAG failure modes, like hallucinations caused by out-of-context search results. Dive in and test it using our Playground, Python SDK, or clone these examples.
Problem 🤔
Many uses for LLMs, including most customer support and employee productivity applications, require effectively connecting LLMs to external knowledge sources. Doing this well is very hard. Current retrieval augmented generation (RAG) methods just take existing information retrieval methods and stuff the results into an LLM prompt. This works for simple demos, but usually isn’t reliable enough for real-world production applications.
Solution 🧠
Superpowered AI offers a simple API that lets you connect external data sources (like product documentation, for example) to LLMs. We leverage proprietary RAG technology we’ve developed (we call it the SuperStack) to dramatically improve performance and reliability for a wide variety of use cases.
Our solution is end-to-end, so you don’t have to worry about stringing together different APIs for different parts of the retrieval and generation pipeline. Here are some key features:
- Support for uploading various types of text files, PDFs, website content, and audio files
- 94 languages supported
- Use our knowledge retrieval pipeline on its own with our Query endpoint, or take advantage of our Chat endpoint for a fully end-to-end solution for building conversational applications connected to external knowledge sources.
- Usage-based pricing, so you only pay for what you use, and $50 in free credits to all new users!
The SuperStack 🦸
The SuperStack has three components that directly tackle the problems with standard RAG pipelines:
AutoQuery → Convert user inputs into well-formed search queries for better retrieval results.
Relevant Segment Extraction (RSE) → Dynamically group clusters of relevant results into longer sections of contiguous text to provide better context to the LLM. This is especially useful for more complex questions, where the answer isn’t contained in a single sentence or paragraph.
AutoContext → Automatically inject descriptive context into text chunks and embeddings, to capture the full context of each chunk of text, reducing the likelihood of poor search results and hallucinations.
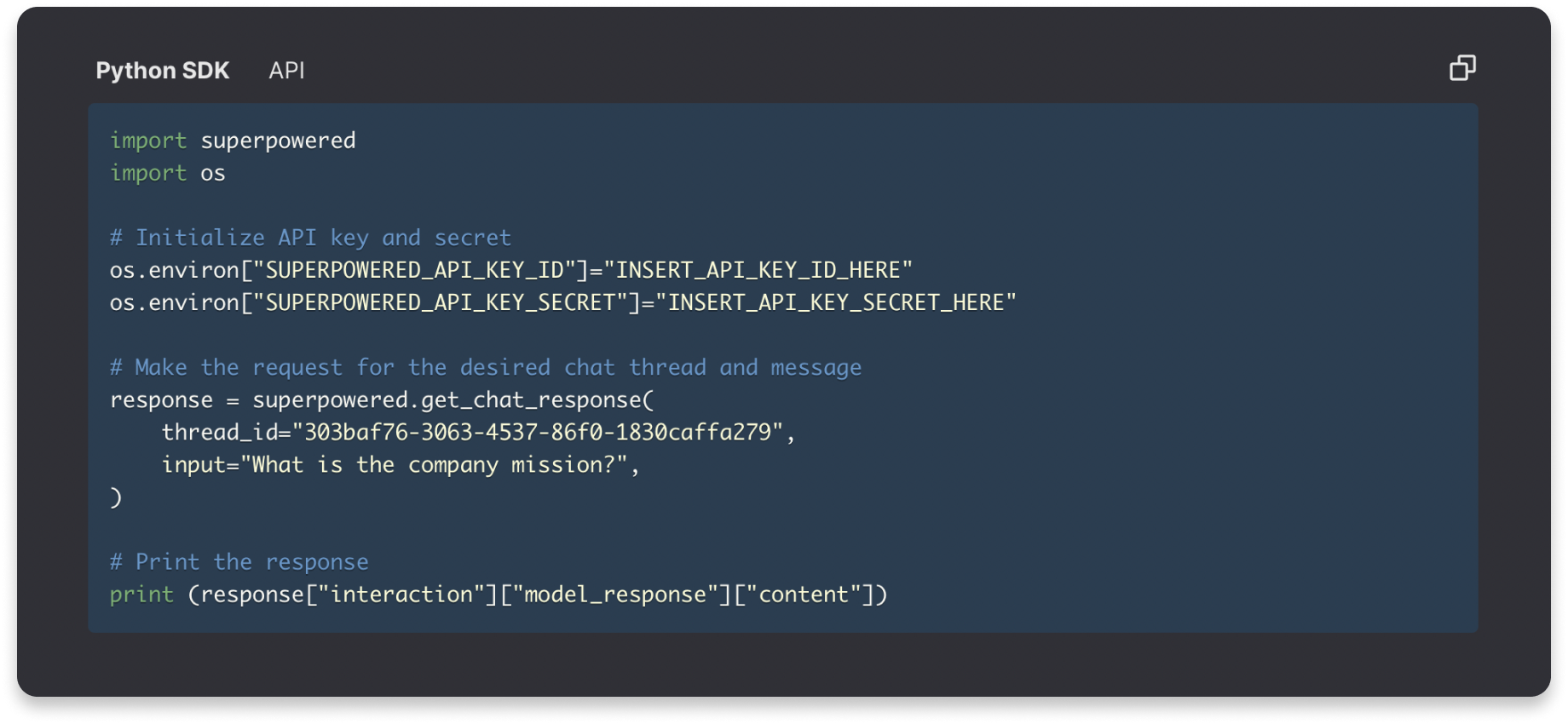
Chat Endpoint 💬
Given that LLM applications often involve conversational interactions, we recently launched our Chat endpoint to make it easy to configure and deploy chat applications that utilize our knowledge retrieval pipeline. We currently support GPT-3.5-Turbo and GPT-4, with more models coming soon.
https://youtu.be/3bnS3ppoRtM?feature=shared
Custom Solutions 🌐
For companies that don’t have the resources or expertise to build their own LLM-based solutions, we’re here to help. Whether you're looking to enhance internal productivity or launch innovative new products with LLMs, we will work with you to bring your vision to life. Our team is dedicated to helping businesses of all sizes leverage the potential of AI to drive efficiency and customer love.
Ask 🙏
- Test it out and share your feedback. If it isn’t working well for your use case, please let us know! We love diving in and solving difficult problems for our customers.
- If you know developers/founders who are looking to build an LLM-based app, please send intros. We love learning about different use cases and the challenges developers are facing.
- Retweet