Atla-1 — One LLM to evaluate them all
A faster, better, stable AI-evaluator to help developers iterate faster when building with LLMs.
At Atla, we train models to act as reliable evaluators of generative AI applications. Our evaluation models are faster, more stable, and align more closely with human annotators than general-purpose LLMs.
The Problem
Benchmarks ≠ user preferences. Developers currently spend huge amounts of time iterating across prompts, models & training data. The only ways to evaluate performance are manual & subjective or slow & unstable. You either trust your gut, hire expensive domain experts, or have to live with the self-bias and instability of GPT-4-based evals.
Our Solution
With Atla, teams can rapidly achieve high performance, discover failure modes, and know the accuracy of their GenAI applications. Our evaluation models are faster, more stable, and align more closely with human annotators than general-purpose LLMs. Atla helps engineers get a clear optimization target for their LLM applications. 🎯
Our 7B eval model compares favorably with GPT-4 on our experiments with real customer data and beats GPT-3.5 as an evaluator on the most important benchmarks:

We have trained on five key metrics to cover the most critical use cases of LLMs:
hallucination: Measures the presence of incorrect or unrelated information.
groundedness: Measures if the answer is factually based on the provided context.
context_relevance: Assesses the retrieved context’s relevance to the query.
recall: Measures how completely the response captures the key facts.
precision: Assesses the relevance of all the information provided.
How it works
- Integrate Atla into your codebase. Use our API as a drop-in replacement for OpenAI.
- Receive reliable scores & critiques that are reproducible.
Using OpenAI's SDK, the following
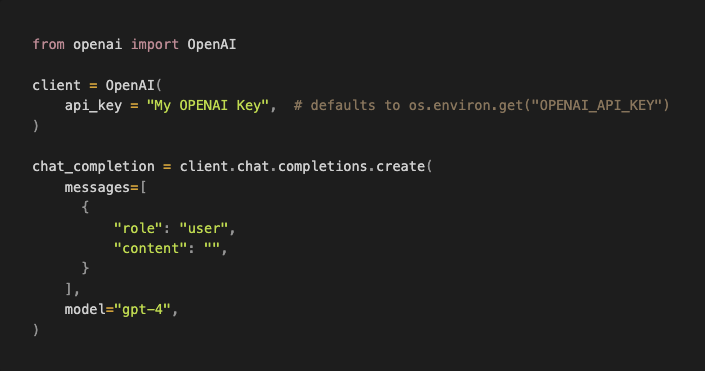
becomes
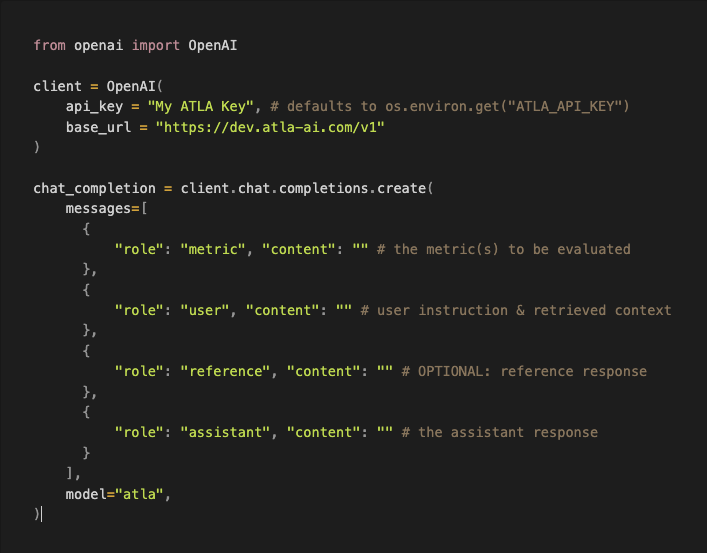
Here’s a sample workbook with human-annotated data from when we built a legal co-pilot. Feel free to try it on your own data!
Our Ask
Have an LLM in production working on generative tasks? Try out our model to evaluate how well your AI application is really working:
- Fill in this quick onboarding form (< 30s) to receive a private API key. We offer $20 of free credits to get you started.
- If you want a demo or want to chat more about your evals, please book a call here.