Helicone - Open-source observability platform for generative AI
Log requests made to OpenAI and track costs, result quality, and latency with one line of code
TL;DR Instead of building tools to monitor your generative AI product, use Helicone to get instant observability of your requests.
Hey everyone, we are the team behind Helicone.
Scott brings UX and finance expertise: 4+ years across Tesla, Bain Capital, and DraftKings.
Justin brings platform and full-stack expertise: 7+ years across Apple 🍎, Intel, and Sisu Data.
We’re on a mission to make it extremely straightforward to observe and manage the use of language models.
❌ The Problem
You’re using generative AI in your product and your team needs to build internal tools for it:
- You want an admin mode to visualize outputs, conversations, or prompt chains
- You don’t know the unit economics of your product, like the average cost of a user or conversation
- Your usage grows and you’re quickly running into rate limits with your provider, but your errors are opaque
- You don’t know when it’s time to fine-tune your model and when you would get cost-savings from it
🪄 Our Solution
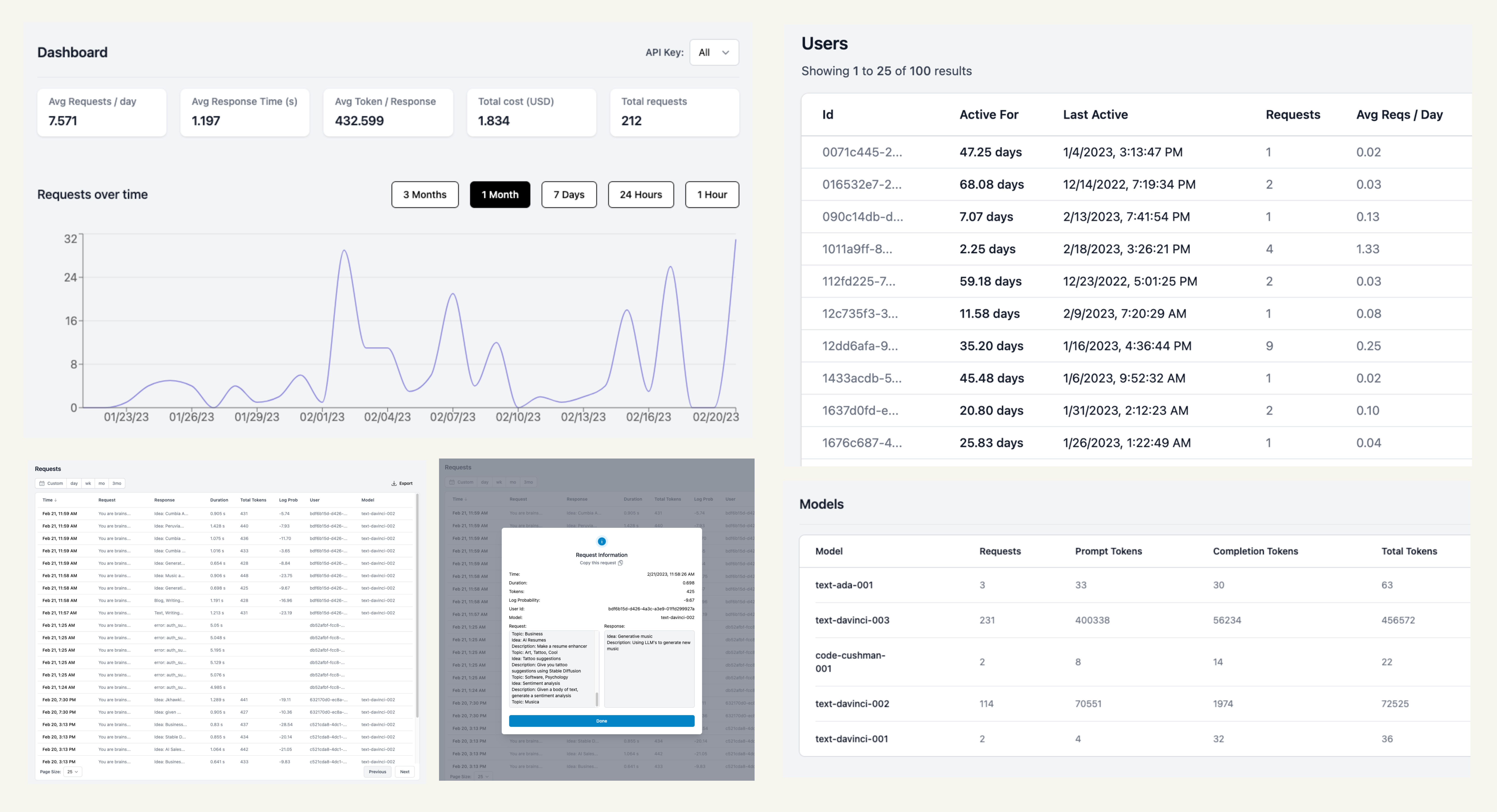
Helicone logs your completions and tracks the metadata of your requests. It is an analytics interface for understanding your metrics broken down by users, models, and prompts with visual cards. It caches your completions to save on bills, and helps you overcome rate limits with intelligent retry techniques.
⚙️ How it works
🎩 Integrate Helicone with one line of code
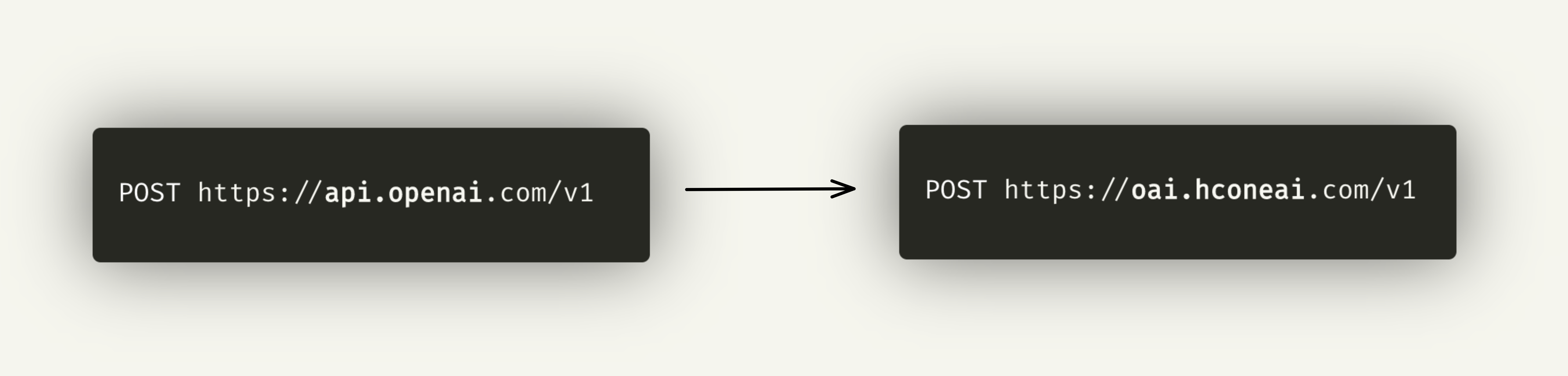
Helicone is a proxy service that executes and logs your requests, secured by Cloudflare workers around the globe to add less than a scratch to your overall latency.
Plug Helicone into wherever you are calling OpenAI with a single line of code by changing the base URL, and immediately get a visual experience for your requests.
🔖 Customize requests with properties
Append custom information like the user, conversation or session id to group requests, then instantly get metrics like the total latency, the users disproportionately driving your OpenAI costs, or the average cost of a user session.
📥 Setup caching and retries
Easily cache your completions so that duplicate requests don’t drive up your bill. Customize your cache for your application’s unique requirements. This removes the latency overhead when you’re experimenting to make development faster.
Configure retry rules when you run into rate limits, or even route your request to another provider when your service is down.
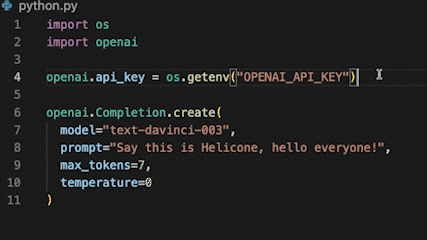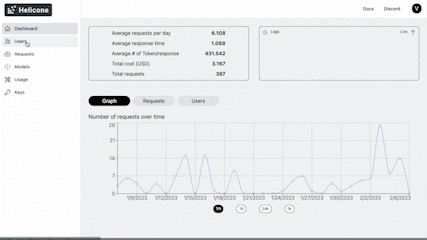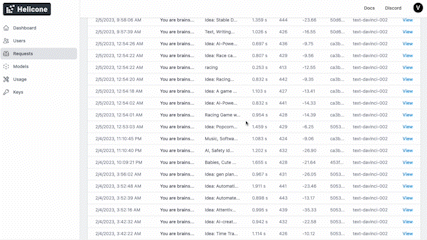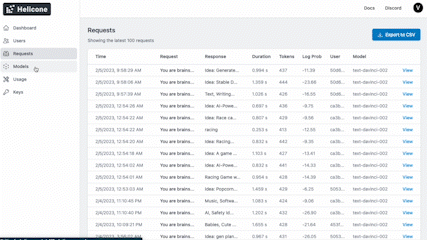
Get started in seconds
- Try it for free at helicone.ai
- Book a call with the team on our calendly
- Join our Discord community
- Email the team at help@helicone.ai
- We’re open source! Check out and support our repository at github.com/Helicone/helicone ⭐