
Reinforcement learning as a service

Hi! We’re Derik and Andrew, and we’re building RunRL: the platform that lets you run reinforcement learning on your AI.
We used to run an AI research lab together, and Andrew dropped out from his RL PhD to provide you the greatest reinforcement learning experience possible.
https://www.youtube.com/watch?v=rPP5YNMA4GE
The problem
For a generic LLM agent, every day is like the first day on the job. Tools and tasks need exhaustive explanations. Even still, agents are too unreliable for deployment.
Our fix
RL fine-tuning produces specialist models that intuitively know what to do. It uses the algorithms that produced DeepSeek R1, but customized for your use case.
Simply give us a reward function that tells us what’s good and what’s bad—and we’ll make your model improve.
Example 1: chemistry
You’re trying to make a model that generates potential drug candidates for COVID. You want them to bind as tightly to the active site of Sars-CoV-2 protease as possible, but using Claude+thinking+web-search only gets you a binding performance of 22. Making a better model is as simple as defining the reward to be the binding performance of the model’s outputs:
def reward(output):
molecule = parse_SMILES(output)
if valid_molecule(output):
return binding_performance(output)
else:
return -1
loading it up on RunRL.com, and hitting run:
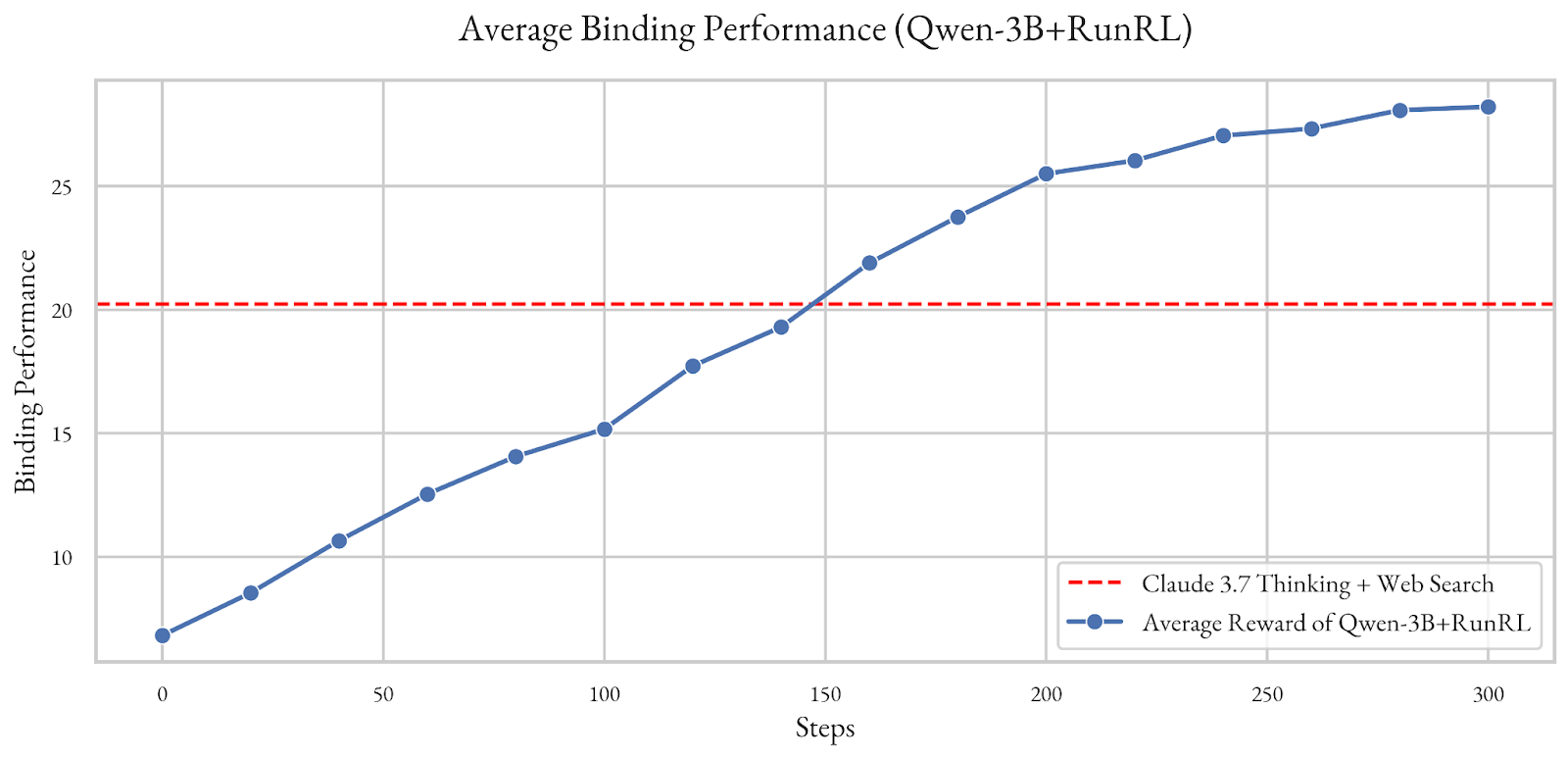
So, a model 175x smaller than Claude learns to outperform the frontier models!
Example 2: agents
You have an OpenAI or Anthropic-based agent, but it’s not as reliable as you’d like it to be. Maybe your agent already does what you want most of the time, but isn’t consistent enough to be trusted in production. RL can help with that too: it reinforces good behavior and makes your agent better at rule-following, information extraction, and document navigation in high-stakes environments. Join our beta here!
Run RL!
If you’re using AI and you want your model to be better, and you have a way of describing what “better” is: you’re ready to run RL.

